Home Office
1 Introduction
With the increasing digitalization of work, the idea of working from home gained more and more traction. For some, it’s a convenience in the face of unnecessary commuting to work (e.g. when you’re a programmer, who doesn’t need to come into work every day while working on a software), for others it can be a crucial part in balancing out work and family demands. It surely has its advantages and disadvantages, both for the worker and for the company, but having it as a possibility increases flexibility and adaptability.
With the global COVID-19 pandemic, working from home drastically shifted from mere convenience to a necessity in many cases, as social distancing guidelines were imposed and businesses had to shut down. This put additional interest into the topic of Home Office - how it’s being implemented, what effect it has on the workers and how it can be improved on.
Beginning in our third wave of inquiry in April, we started to ask our participants various questions about their experience regarding Home Office. With the exception of June, where a part of the questions needed to be reduced in order to gather data on work and ageing, we then continued presenting our participants the same items monthly. Below, You can see some descriptive statistics about various topics connected to working from home. Please note that these results present only an overview of our data, and causal interpretations can exclusively be made after rigorous analysis, published elsewhere. Feel free, however, to get inspirations for future research!
2 Average Time Spent in Home Office
Plot
home_office_T1 = data.frame(
label = c("In Home Office", "Out of Home Office"),
percent = round(c(mean(data_HO$T1_home_office, na.rm = T),100-mean(data_HO$T1_home_office, na.rm = T)), digits = 2)
)
home_office_T1 <- home_office_T1 %>%
arrange(desc(label)) %>%
mutate(ypos = cumsum(percent)- 0.5*percent)
# Code for making the numbers in the pie chart nicely positioned
home_office_T1$ypos = c(44.2,92.5)
#Nicer positioning of the labels inside the Pie-Chart by manually adjusting the calculated values from above
mean_HO_T1 = ggplot(home_office_T1, aes(x="", y=percent, fill = label))+
#aes(x="",...) for pie chart
geom_bar(width = 1, stat = "identity", color = "white", alpha = .9) +
#stat = "identity" for taking the exact numbers from the dataframe, without further calculations; color = "white" for the outlining
scale_fill_manual(values = c("#bdd7e7","#3182bd"))+
#colours taken from colour_scale_brewer, Blue. Names of colours taken from https://colorbrewer2.org/#type=sequential&scheme=Blues&n=5
coord_polar("y", direction = -1)+
# direction of the parts
geom_text(aes(y = ypos, label = paste0(percent, '%')), size=6, colour = "#3e3f3a") +
# paste0 for creating (a vector of) strings out of numeral data
# For some reason, font_colour didn't overwrite the font colour inside the chart (earlier it did...)
guides(fill=guide_legend(title="Average proportion of worktime spent...", title.position = "top"))+
theme_void()+
# losing all other lines for sleeker look
theme(legend.position="bottom", legend.text = element_text(size = 14), legend.title = element_text(size = 14.5))+
font_colour
mean_HO_T1
# presenting the plot
density_HO_T1 = ggplot(data_HO, aes(T1_home_office))+
theme_classic()+
geom_histogram(binwidth=10,col="#3182bd", fill = "#6baed6", alpha = .4)+
# binwidth = how wide should the individual coloums be? col for the linecolour, fill for the filled colour
geom_vline(aes(xintercept=mean(T1_home_office, na.rm=T)), linetype="dashed", size= 0.5)+ #Line representing the mean
labs(x="Percentage of worktime spent in Home Office", y = "Amount of participants")+
scale_x_continuous(breaks = seq(0,100,10), labels = paste0(seq(0,100,10), '%')) +
# Indicating the scale size and labels; seq to be read like: "Make a sequence from 0 to 100, going in steps of 10
scale_y_continuous(breaks=seq(0, 1500, 250))+
theme(axis.text=element_text(size=12), axis.title = element_text(size = 14)) +
font_colour
density_HO_T1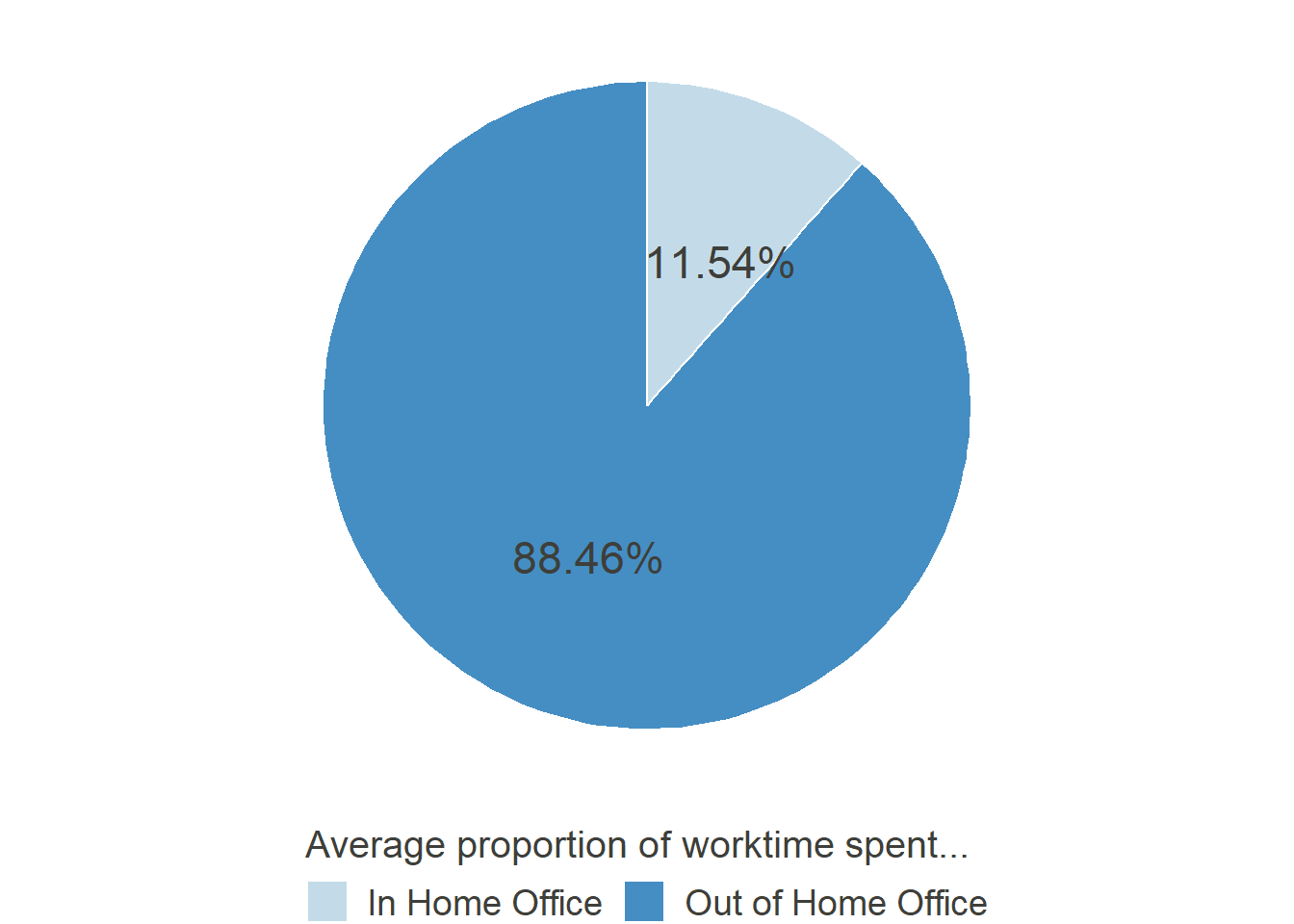
Percentage of time worked from home in December 2019
Additional Information
In December of 2019, when the coronavirus was just one of many news stories from abroad, we coincidentally asked the participants of our study:
“What percentage of Your worktime do You work from home (Home Office)?”
The following graphs show the average proportion of time spent in Home Office and how the percentages were distributed back then.
## For details on the code for the plots, please change to the "Plots"-Tab and unfold the code there. ##
#cache.whatever inside the chunk options tells the chunk, that it has to be invalidated, as soon as one of these variables change. Otherwise, changing the plots in the chunk above doesn't invalidate this chunk and the lastly cached version will be displayed.
mean_HO_T1
density_HO_T1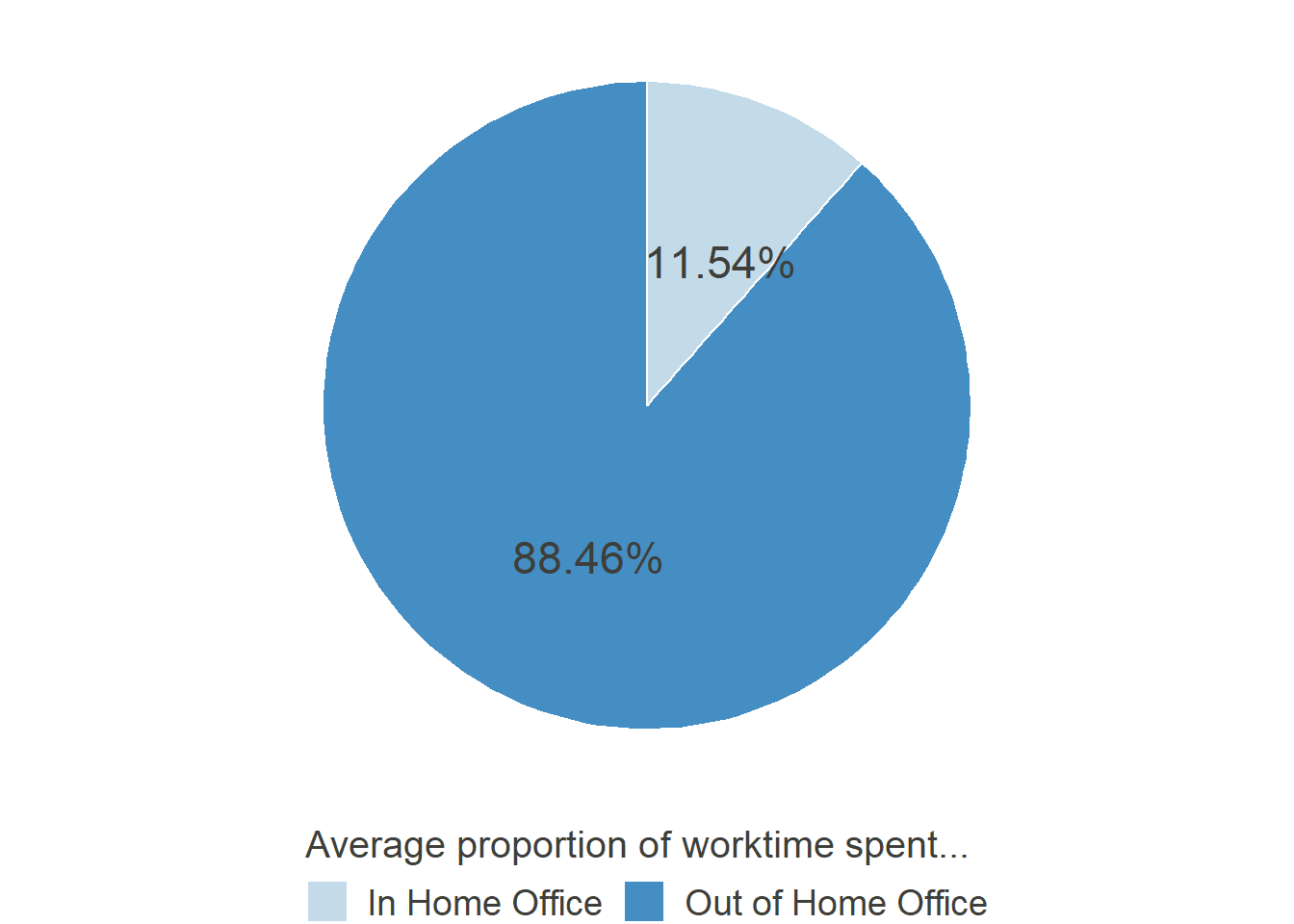
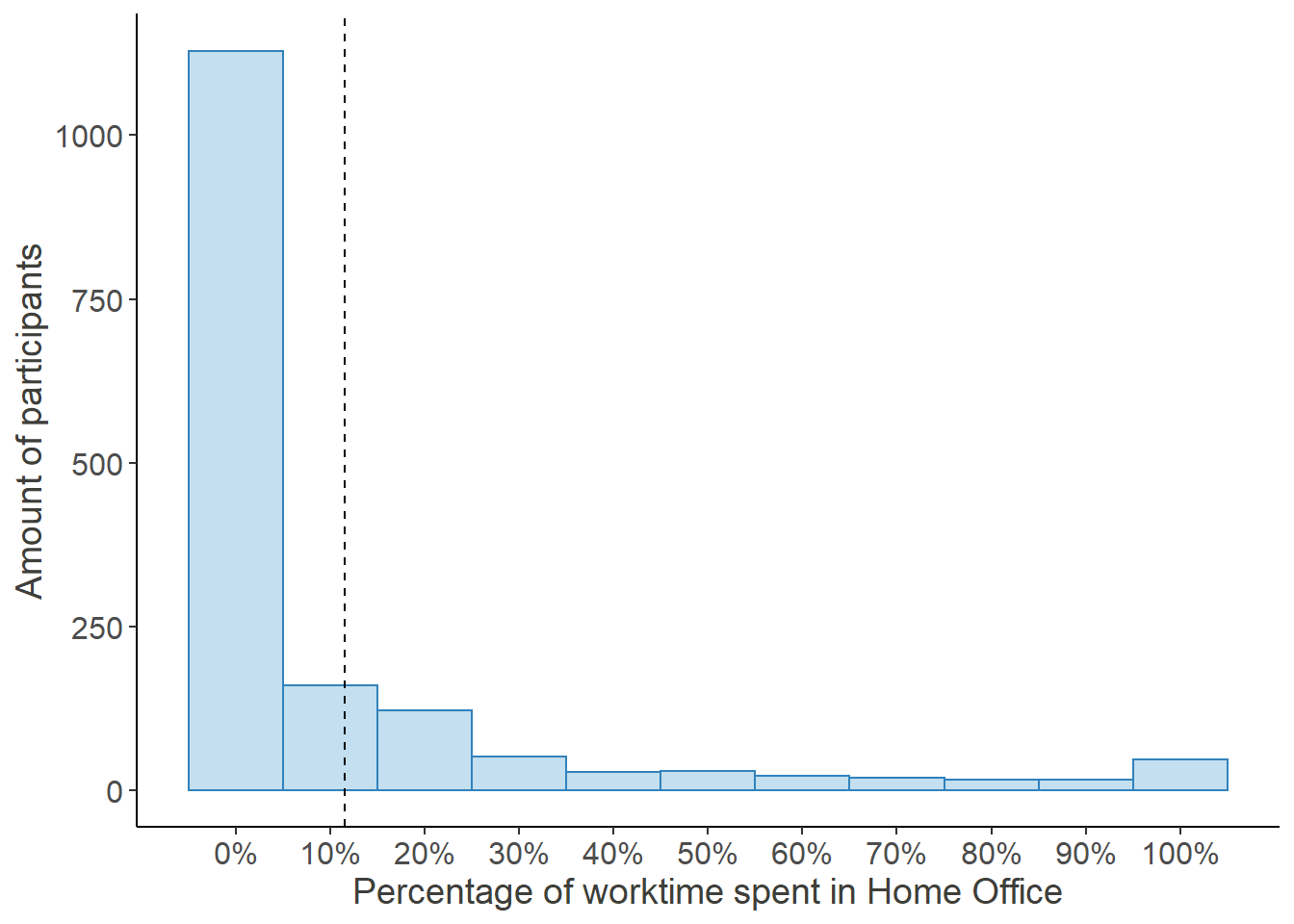
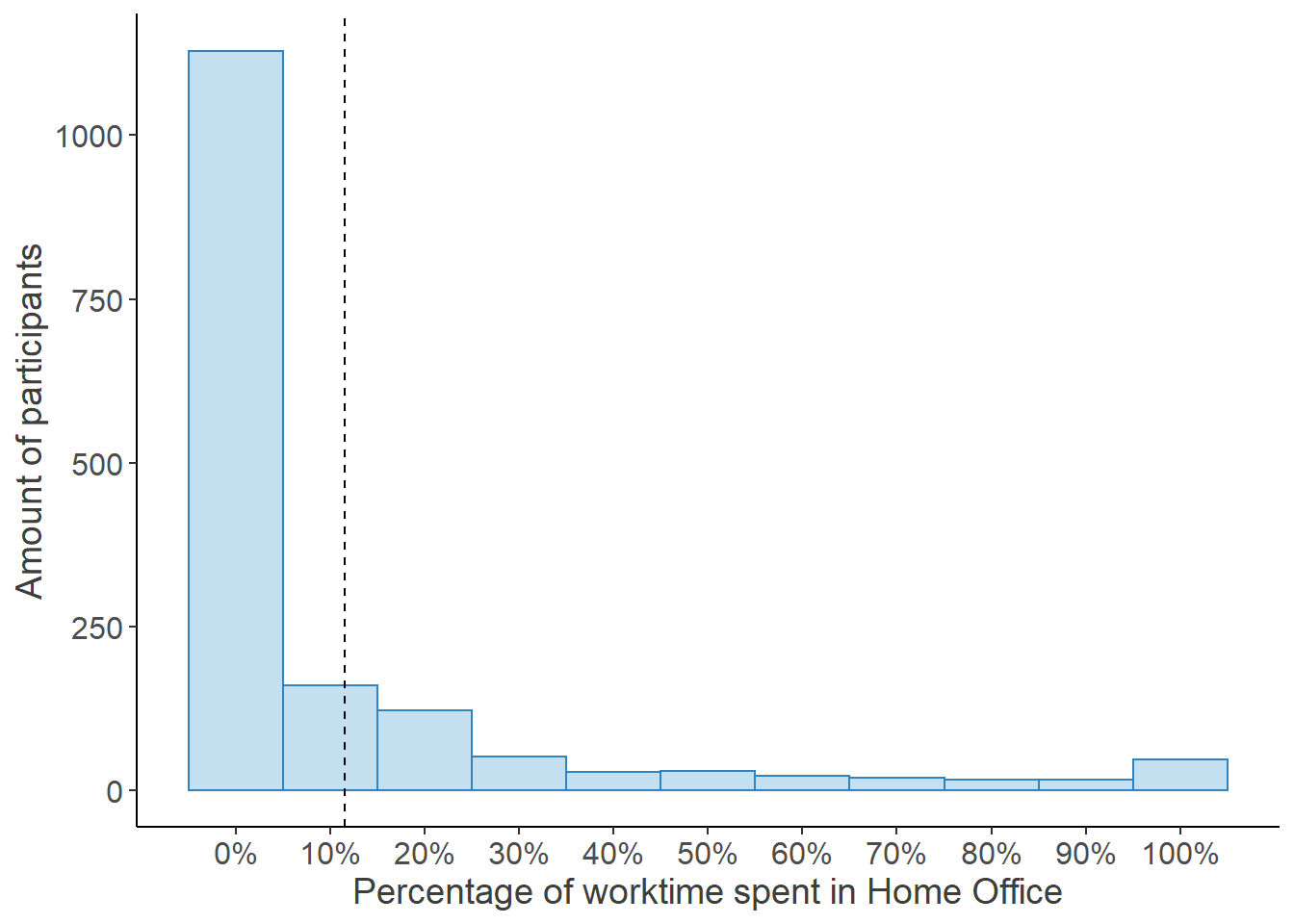
Percentage of time worked from home in December 2019
As can be seen, before the COVID-19 Crisis hit, work from home was rather sparse. Only 725 of the 1639 participants, who answered this question, had indicated that they worked from home at all (equaling 44.23%)
2.1 Development over Time
Plots
#HO6
HO_Perc = select(data_HO,ends_with("_HO6"))
# grep searches for patterns in a given Vector (in this case, the pattern "_HO6" in names(data_HO)). This allows easy finding of the same variable over different time points
HO_Perc_rel = data.frame(
matrix(
NA,
nrow = length(months_compl),
ncol = 5,
dimnames = list(c(),c("month","mean_perc", "sd_perc", "missing", "mis_sd"))
)
)
HO_Perc_rel$month = as.factor(months_compl)
for (i in 1:length(months_compl)) {
#means
if (HO_Perc_rel[i,1] %in% months_miss) {
HO_Perc_rel[i,2] = mean(HO_Perc[,paste0("T",i+2,"_HO6")], na.rm = T)
}
#sds
if (HO_Perc_rel[i,1] %in% months_miss) {
HO_Perc_rel[i,3] = sd(HO_Perc[,paste0("T",i+2,"_HO6")], na.rm = T)
}
}
for (i in 1:length(months_compl)) {
#missing mean
if (HO_Perc_rel[i,1] %in% c("May '20","July '20")) {
HO_Perc_rel[i,4] = HO_Perc_rel[i,2]
} else if (HO_Perc_rel[i,1] == "June '20"){
HO_Perc_rel[i,4] = mean(c(HO_Perc_rel[i-1,2],HO_Perc_rel[i+1,2]))
}
#missing sd
if (HO_Perc_rel[i,1] %in% c("May '20","July '20")) {
HO_Perc_rel[i,5] = HO_Perc_rel[i,3]
} else if (HO_Perc_rel[i,1] == "June '20"){
HO_Perc_rel[i,5] = mean(c(HO_Perc_rel[i-1,3],HO_Perc_rel[i+1,3]))
}
}
HO_Perc_plot = ggplot(HO_Perc_rel, aes(x=month, y = mean_perc)) +
geom_line(aes(group=1), col= "#3182bd", size = 1.5)+
geom_line(aes(x=month, y=missing, group =1,color = "#3182bd"), col= "#3182bd", size = 1.5, linetype = "dashed" )+
# for the connecting dashed line
geom_point(col= "#3182bd", size = 3)+
# for the points at every month
geom_ribbon(aes(y=mean_perc, ymin = mean_perc - (sd_perc/2), ymax = mean_perc + (sd_perc/2), group = 1),fill="#3182bd", alpha=0.4) +
geom_ribbon(aes(y=missing, ymin = missing - (mis_sd/2), ymax = missing + (mis_sd/2), group = 1),fill="#3182bd", alpha=0.3) +
# only half a SD around the mean, because the whole SD would have filled the whole scale
coord_cartesian(ylim = c(0,60))+
theme_minimal()+
scale_x_discrete(limits = months_compl, name ="" )+
scale_y_continuous(breaks = seq(0,60,10), labels = paste0(seq(0,60,10), "%"), name = "Percentage of a week \nworked from home")+
labs(caption = "Note: Data was missing for June. Ribbon represents 1SD around the mean.")+
theme(axis.text.x = element_text(angle = 45, hjust = 1))+
font_colour
HO_Perc_plot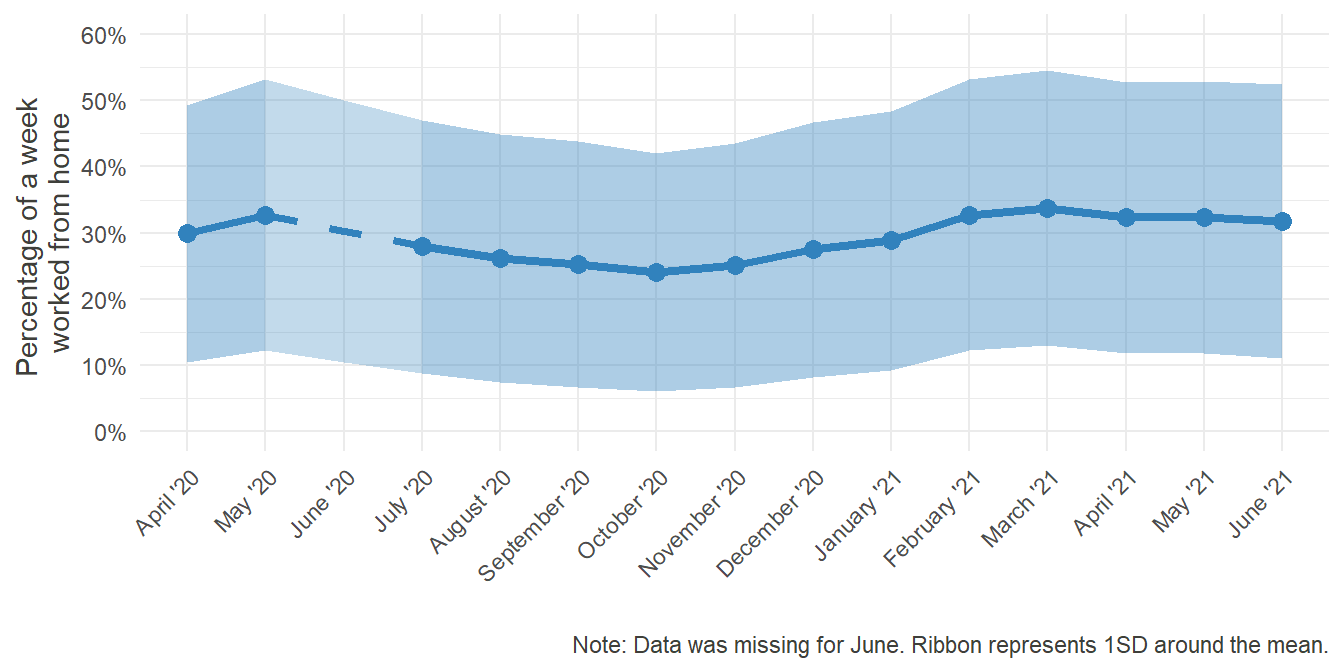
## Old way of calculating the Means/SDs and extrapolating their missing value in between.
## New code with for- and if-constructions should calculate all the required data by itself, but as a safety, we leave this old code here
# HO_Perc_rel = data.frame(
# month = as.factor(months_compl),
# mean_perc = c(
# mean(HO_Perc$T3_HO6, na.rm = T),
# mean(HO_Perc$T4_HO6, na.rm = T),
# NA,
# mean(HO_Perc$T6_HO6, na.rm = T),
# mean(HO_Perc$T7_HO6, na.rm = T),
# mean(HO_Perc$T8_HO6, na.rm = T),
# mean(HO_Perc$T9_HO6, na.rm = T),
# mean(HO_Perc$T10_HO6, na.rm = T),
# mean(HO_Perc$T11_HO6, na.rm = T),
# mean(HO_Perc$T12_HO6, na.rm = T)
# ),
# sd_perc = c(
# sd(HO_Perc$T3_HO6, na.rm = T),
# sd(HO_Perc$T4_HO6, na.rm = T),
# NA,
# sd(HO_Perc$T6_HO6, na.rm = T),
# sd(HO_Perc$T7_HO6, na.rm = T),
# sd(HO_Perc$T8_HO6, na.rm = T),
# sd(HO_Perc$T9_HO6, na.rm = T),
# sd(HO_Perc$T10_HO6, na.rm = T),
# sd(HO_Perc$T11_HO6, na.rm = T),
# sd(HO_Perc$T12_HO6, na.rm = T)
# )
# )
# # Data-Frame with the means and standard deviations of the percentages of time Worked in Home Office, Long Format (Because of the many NAs, ggplots stat = "mean" could have shown errrors)
# # Usually Colmeans would have maybe done the trick, but we don't have the data for every month, and need an NA, so that we can fill that with in the plot
#
# # For every new wave, that is entered, this new TX_HOY needs to be added in these dataframes and NAs in the "Missing" cols
#
# HO_Perc_rel$missing = c(NA,
# HO_Perc_rel[2,2],
# mean(c(HO_Perc_rel[2,2],HO_Perc_rel[4,2])),
# HO_Perc_rel[4,2],
# NA,
# NA,
# NA,
# NA,
# NA,
# NA)
# #Extrapolating the missing value in June to make a separate connecting line between May and July in the graph
# HO_Perc_rel$mis_sd = c(NA,
# HO_Perc_rel[2,3],
# mean(c(HO_Perc_rel[2,3],HO_Perc_rel[4,3])),
# HO_Perc_rel[4,3],
# NA,
# NA,
# NA,
# NA,
# NA,
# NA)
HO_Perc_long = gather(HO_Perc, month, percentage)
HO_Perc_long$month = factor(HO_Perc_long$month, levels = names(HO_Perc), labels = months_miss)
## Here are some attempts to show the distribution of the percentages over time, to show that the middle part of the distribution remained sparse and only the right border grew, accounting for the overall increase in Home Office time.
HO_Perc_ani = ggplot(HO_Perc_long, aes(percentage)) +
theme_classic()+
geom_histogram(binwidth=10,col="#3182bd", fill = "#6baed6", alpha = .4)+
labs(x="Percentage of worktime spent in Home Office", y = "Amount of participants")+
scale_x_continuous(breaks = seq(0,100,10), labels = paste0(seq(0,100,10), '%')) +
scale_y_continuous(breaks=seq(0, 1500, 250))+
theme(axis.text=element_text(size=12), axis.title = element_text(size = 14)) +
font_colour +
# normal ggplot plot
transition_states(month,
transition_length = 2,
state_length = 1) +
# by adding this part, it becomes a animated plot. the first argument indicates, by which variable the states should be calculated
ggtitle('{closest_state}') +
# for the title to indicate the respective month
ease_aes('cubic-in-out')
# for nicer transitioning
animate(HO_Perc_ani, renderer = magick_renderer(), duration = length(months_compl), fps = 10)
HO_Perc_dens = ggplot(HO_Perc_long, aes(percentage, y=..density.., fill = month, color = month)) +
theme_classic()+
theme(legend.title = element_blank())+
geom_density(alpha = .1)+
labs(x="Percentage of worktime spent in Home Office", y = "Density", legend = NULL)+
scale_x_continuous(breaks = seq(0,100,10), labels = paste0(seq(0,100,10), '%')) +
scale_fill_brewer(palette="Blues", direction = -1) +
scale_color_brewer(palette="Blues", direction = 1) +
theme(axis.text=element_text(size=12), axis.title = element_text(size = 14)) +
font_colour
HO_Perc_dens
HO_Perc2 = select(data_HO, ID, ends_with("_HO6"))
HO_Perc2 = add_column(HO_Perc2, T5_HO6 = NA, .before = "T6_HO6")
HO_Perc2$T5_HO6 = as.numeric(HO_Perc2$T5_HO6)
HO_Perc_long2 = reshape(
HO_Perc2,
varying = grep("HO6", names(HO_Perc2), value = T),
v.names = "Percentage",
idvar = "ID",
direction = "long",
timevar = "month"
)
HO_Perc_long2$month = factor(HO_Perc_long2$month, labels = months_compl)
HO_perc_violplot = ggplot(HO_Perc_long2, aes(month,Percentage)) +
geom_violin(trim = T,col= "#6baed6" ) +
geom_jitter(width = 0.05, size = 0.05,col= "#3182bd", alpha = 0.3) +
geom_line(aes(group = 1), stat = "summary", fun = mean, col= "#3182bd", size = 1)+
geom_point(col= "#3182bd", size = 2.5, stat = "summary", fun = mean)+
geom_line(aes(group = 1), stat = "summary", fun = median, col= "#6baed6", size = 1, linetype = 4)+
geom_point(col= "#6baed6", size = 2.5, stat = "summary", fun = median, shape = 18)+
# for the points at every month
# only half a SD around the mean, because the whole SD would have filled the whole scale
coord_cartesian(ylim = c(0,100))+
theme_minimal()+
scale_x_discrete(limits = months_compl, name ="" )+
scale_y_continuous(breaks = seq(0,100,10), labels = paste0(seq(0,100,10), "%"), name = "Percentage of a week worked from home")+
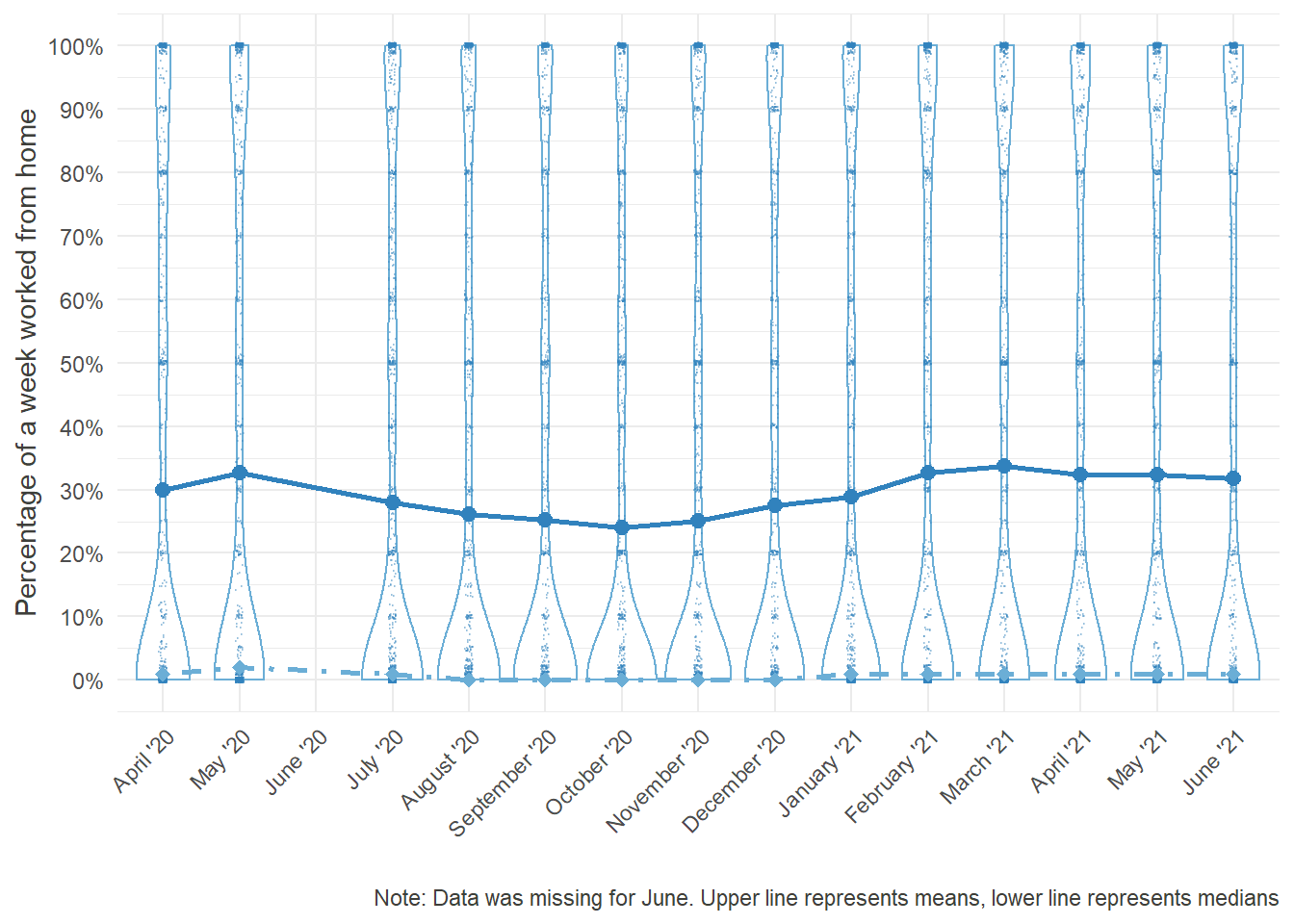
labs(caption = "Note: Data was missing for June. Upper line represents means, lower line represents medians")+
theme(axis.text.x = element_text(angle = 45, hjust = 1))+
font_colour
HO_perc_violplot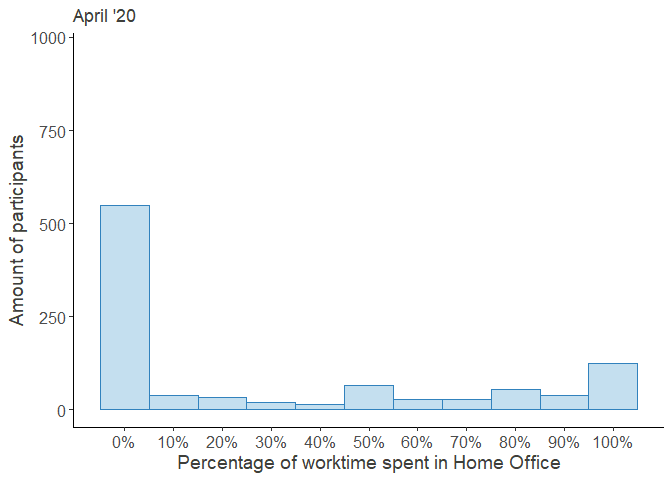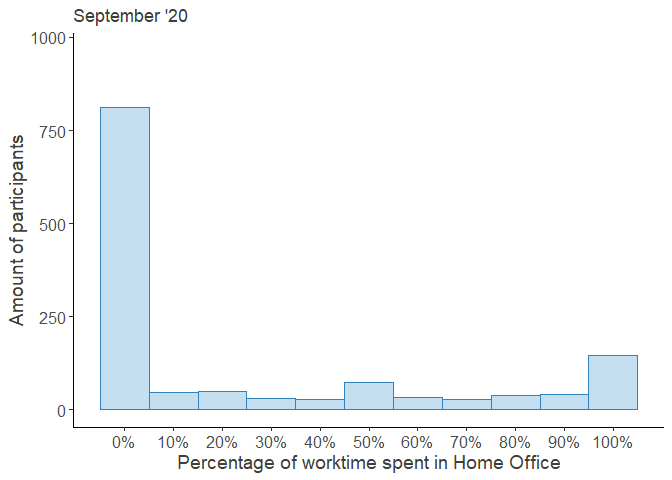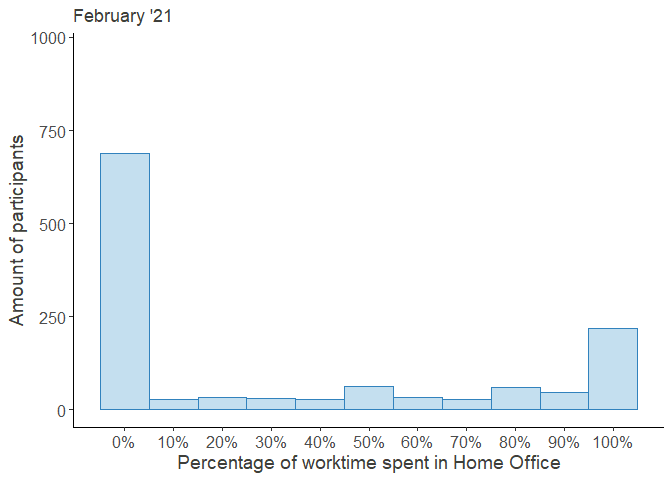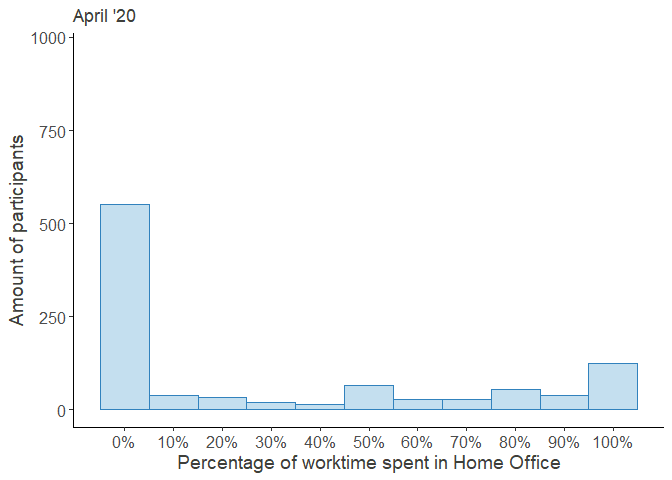
Additional Information
Since December, the first time we asked our participants about their work in the Home Office again was in April of 2020, and then, with the exception of June, monthly. Specifically, we wanted to know:
“In the past 4 weeks (Since the beginning of …): What percentage of Your average work week did you spend in Home Office?”
## For details on the code for the plots, please change to the "Plots"-Tab and unfold the code there. ##
HO_Perc_plot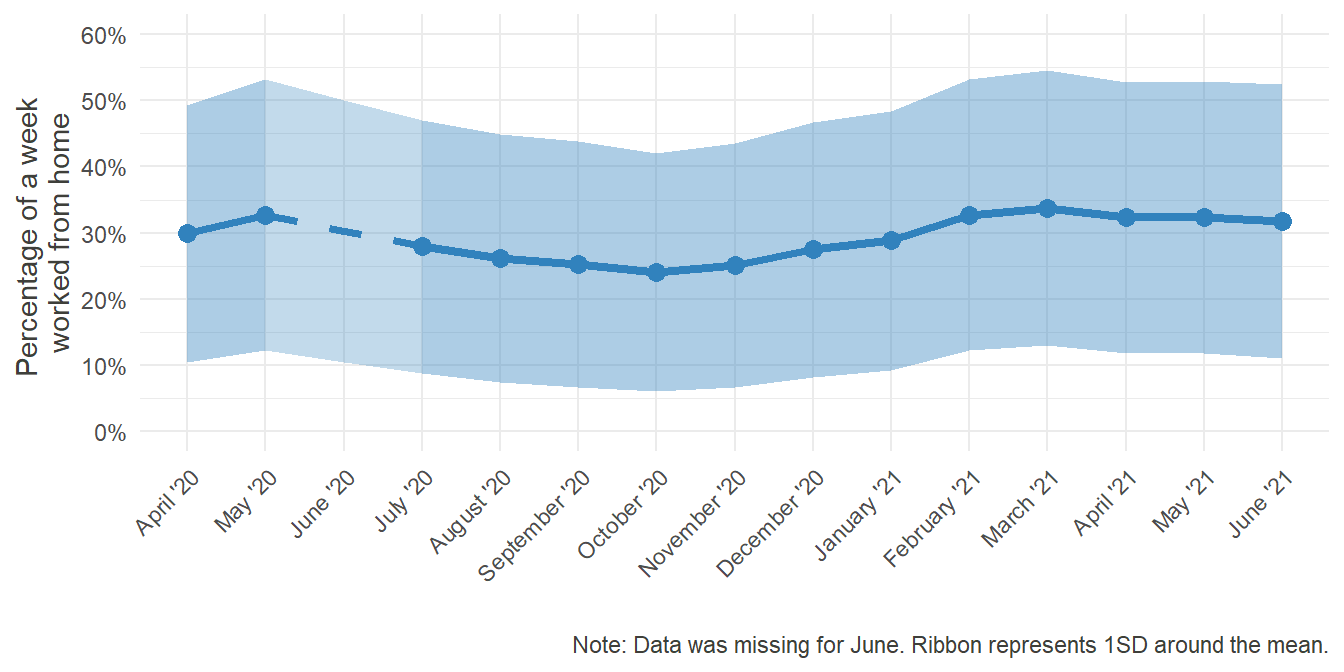
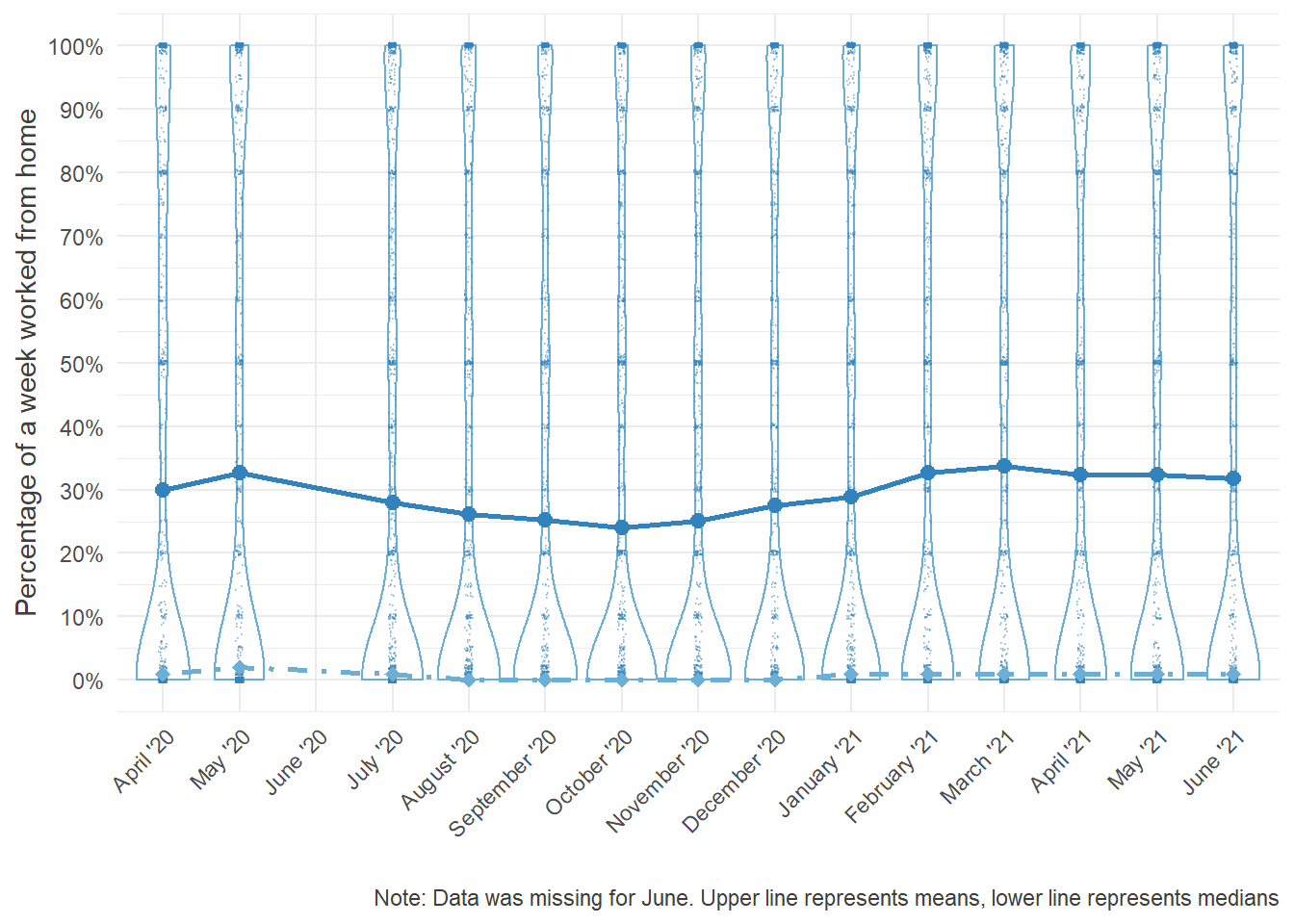
Notably and expectedly, the mean time spent in Home Office grew as the pandemic unfolded. At its peak in May, the percentage was three times as high as in December. Furthermore, as infection rates dropped in the summer and some form of “new normality” emerged, working from home steadily declined. Remembering, however, how disproportionate the various rates were distributed in December, it would be interesting to look at how the distribution changed over time:
## For details on the code for the plots, please change to the "Plots"-Tab and unfold the code there. ##
animate(HO_Perc_ani, renderer = magick_renderer(), duration = length(months_compl), fps = 10)
HO_Perc_dens
HO_perc_violplot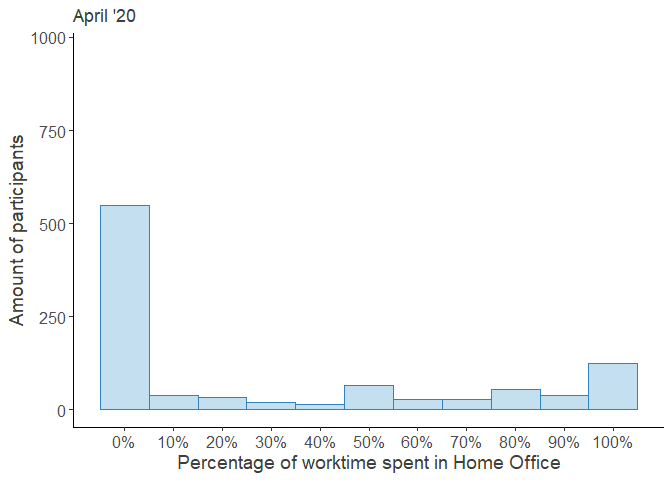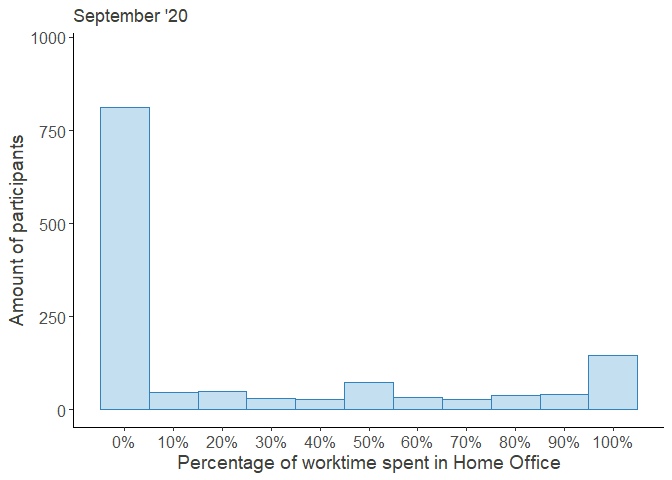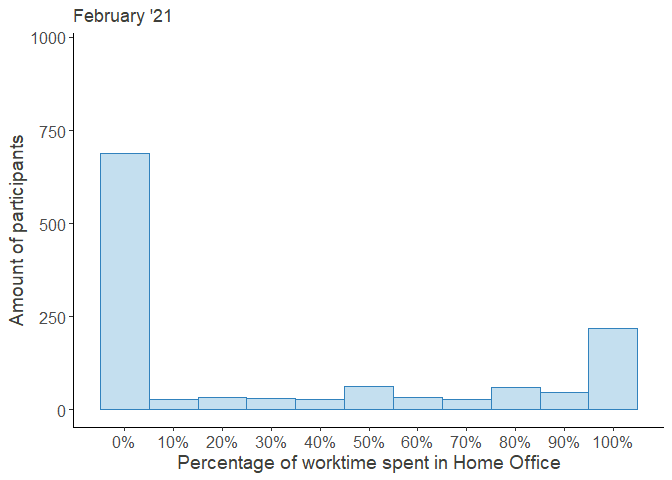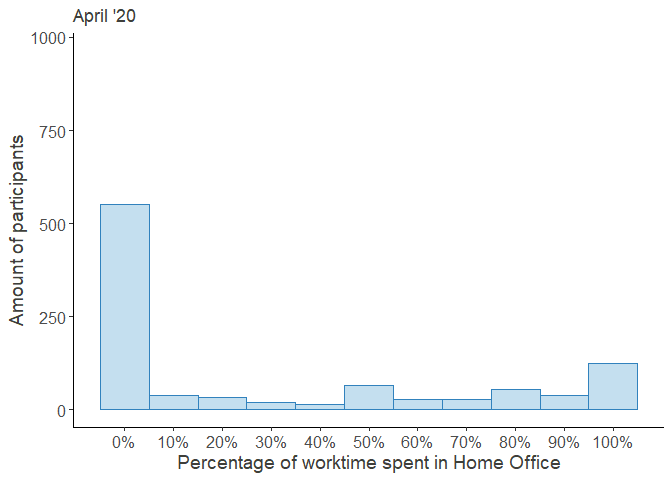
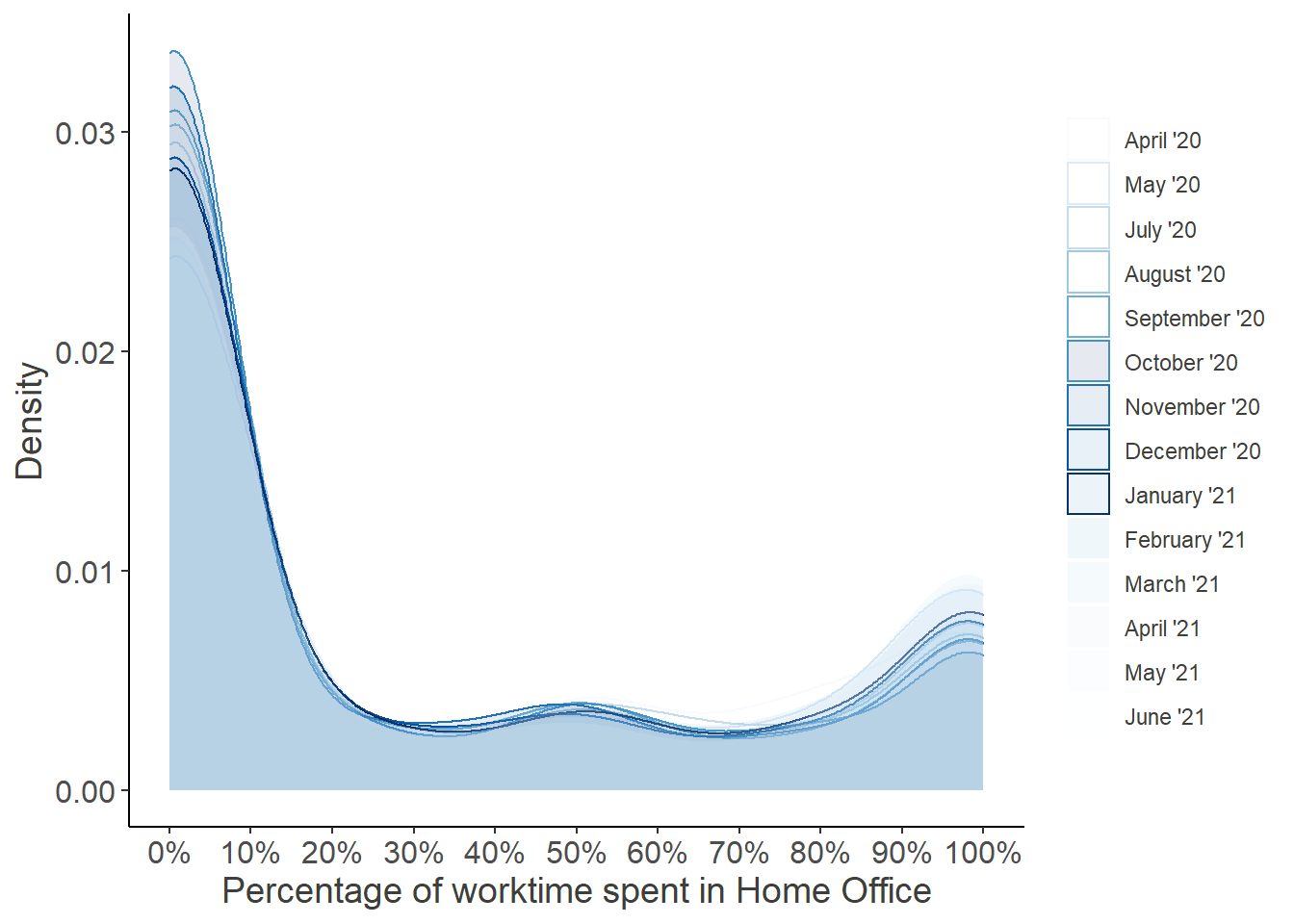
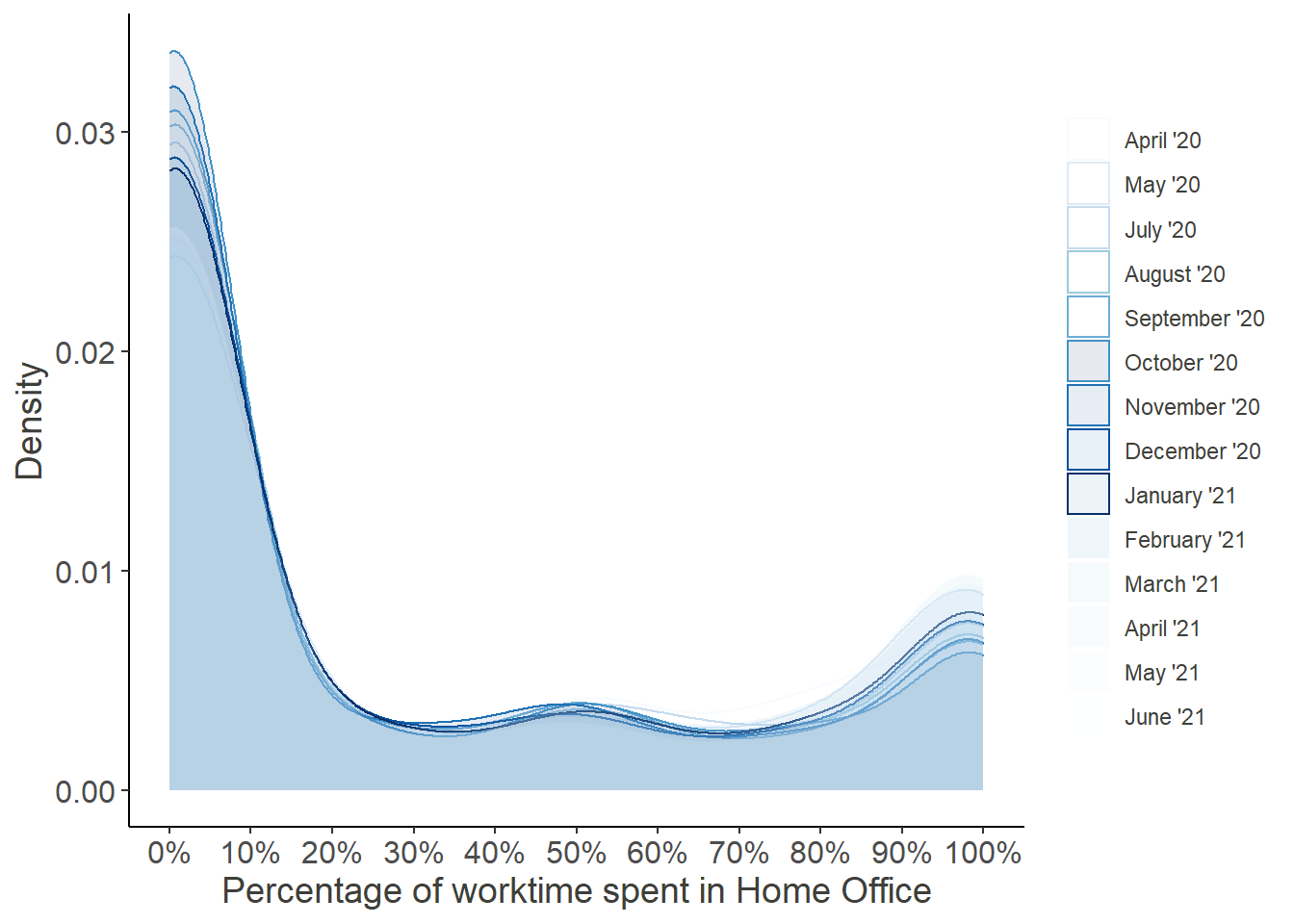
Looking at these distributions it grows clear that the increased percentage worked from home was mainly driven by the outer right part of the distribution, i.e. the people who worked from home entirely, while the rest continued working fully at their regular workplace.
Moreover, the decrease over time seems to be attributed to the workers, who returned from their Home Offices, while the middle of the distribution remained largely unchanged. Note that the steep increase in October was partially due to a resampling of new participants in order to compensate for the gradual dropout.
3 Possibility to Work from Home
Plots
# 1 = Not possible, 2 = Possible
HO_Pos_T3 = round(data.frame(
pre = c(length(which(data_HO$T3_HO1 == 2)),
length(which(data_HO$T3_HO1 == 1 ))) /length(which((data_HO$T3_HO1 != "NA"))),
post = c(length(which(data_HO$T3_HO4 == 2)),
length(which(data_HO$T3_HO4 == 1 ))) /length(which((data_HO$T3_HO4 != "NA")))
)*100,digits = 2)
HO_Pos_T3 <- HO_Pos_T3 %>%
mutate(ypos_pre = cumsum(pre)- 0.5*pre) %>% #Positions for the labels inside the Pie-Chart
mutate(ypos_post = cumsum(post)- 0.5*post)
HO_Pos_T3$labels = c("Yes","No")
HO_Pos_pre = ggplot(HO_Pos_T3, aes(x="", y= pre, fill = labels)) +
geom_bar(width = 1, stat = "identity", color = "white", alpha = .9) +
scale_fill_discrete(breaks=c("Yes","No")) +
scale_fill_manual(values = c("#3182bd","#bdd7e7"))+
coord_polar("y")+
geom_text(aes(y = ypos_pre, label = paste0(pre, '%')), size=6, colour = "#3e3f3a") +
guides(fill=guide_legend(title="Before the Pandemic", title.position = "top"))+
theme_void()+
theme(legend.position="bottom", legend.text = element_text(size = 14), legend.title = element_text(size = 14.5) )+
font_colour
HO_Pos_pre
HO_Pos_post = ggplot(HO_Pos_T3, aes(x="", y= post, fill = labels)) +
geom_bar(width = 1, stat = "identity", color = "white", alpha = .9) +
scale_fill_manual(values = c("#3182bd","#bdd7e7"))+
coord_polar("y")+
geom_text(aes(y = ypos_post, label = paste0(post, '%')), size=6, colour = "#3e3f3a") +
guides(fill=guide_legend(title="Since March", title.position = "top"))+
theme_void()+
theme(legend.position="bottom", legend.text = element_text(size = 14), legend.title = element_text(size = 14.5))+
font_colour
HO_Pos_post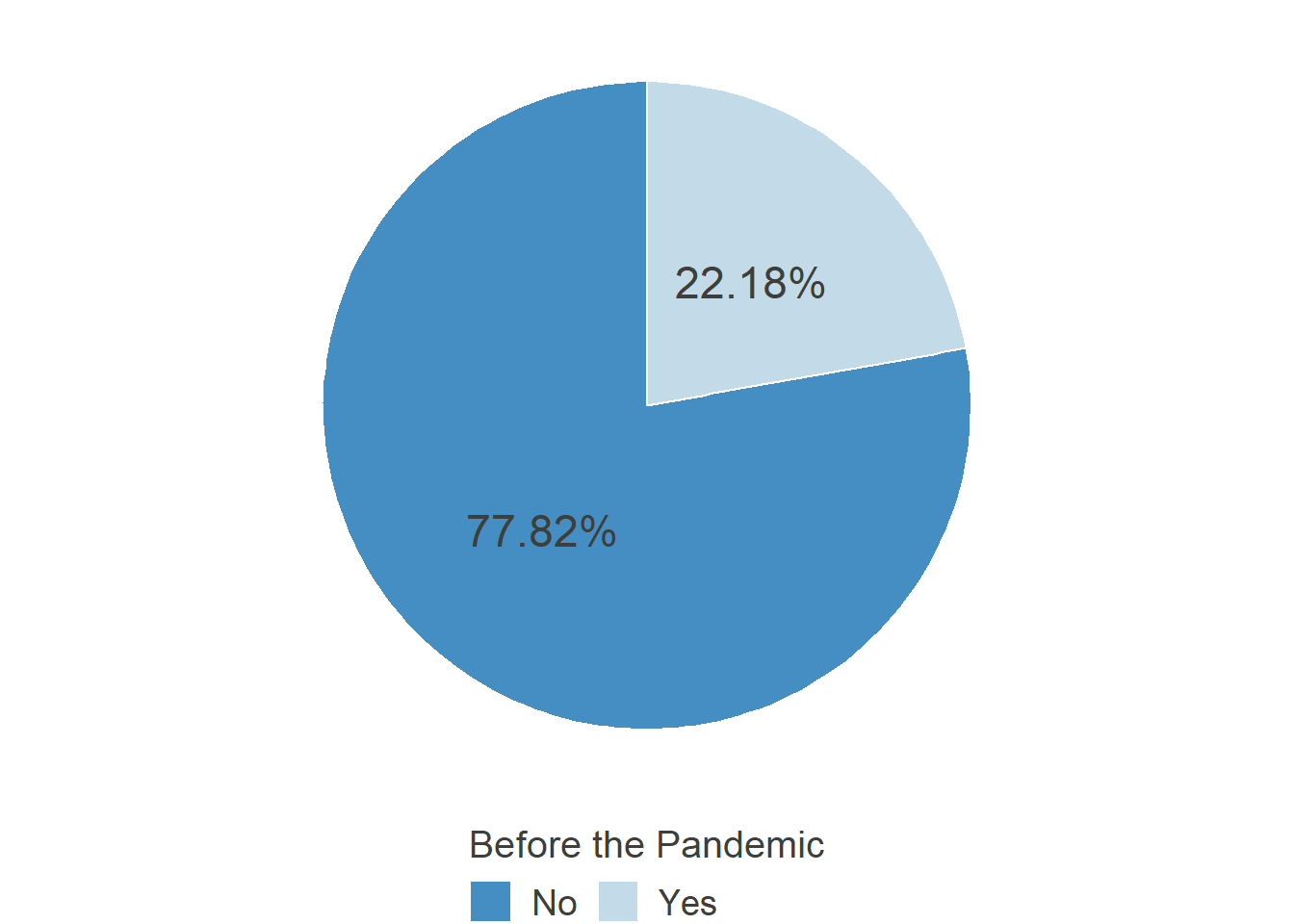
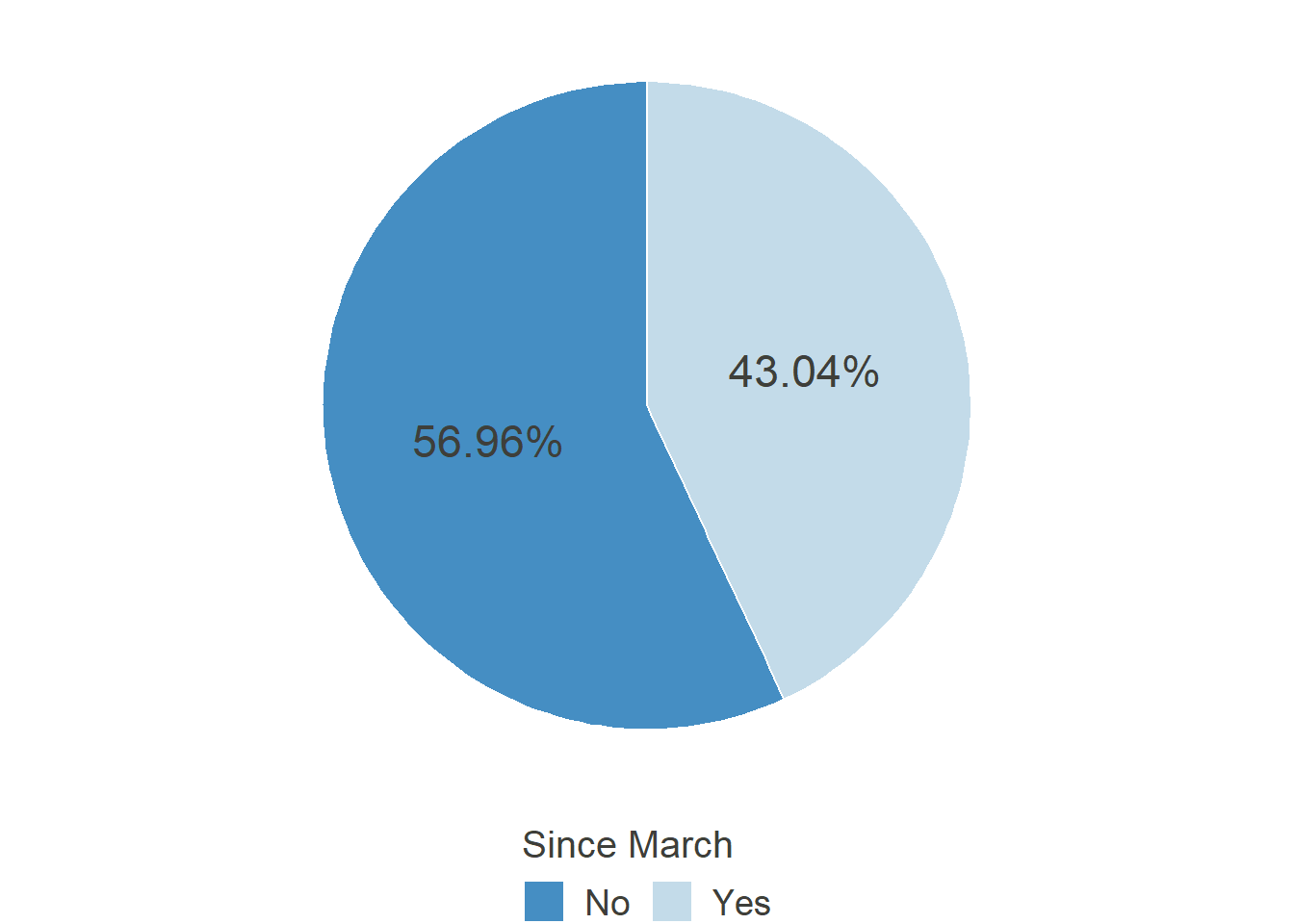
Allowed to work from home
Additional Information
One important aspect when talking about Home Office is the extend, to which employers allow their employees to work from home. A manager could have many reasons not to give that permission, such as fearing loss of control over subordinates, thinking that work won’t be done in time, doubts about feasibility or just personal preference. Looking at how the constraint of the pandemic and the measures undertaken by the German government influenced the permission of employers might give an insight into how sound those arguments against Home Office really were.
In March 2020 the coronavirus hit Germany. Many businesses had to shut down, public life was reduced to a bare minimum. In April, we asked our participants two questions:
“Before the COVID-19 Pandemic (Corona-Crisis): In general, did You have the possibility to work in Home Office?”
“During the past 4 weeks (Since the beginning of March): In general, did You have the possibility to work in Home Office?”
## For details on the code for the plots, please change to the "Plots"-Tab and unfold the code there. ##
HO_Pos_pre
HO_Pos_post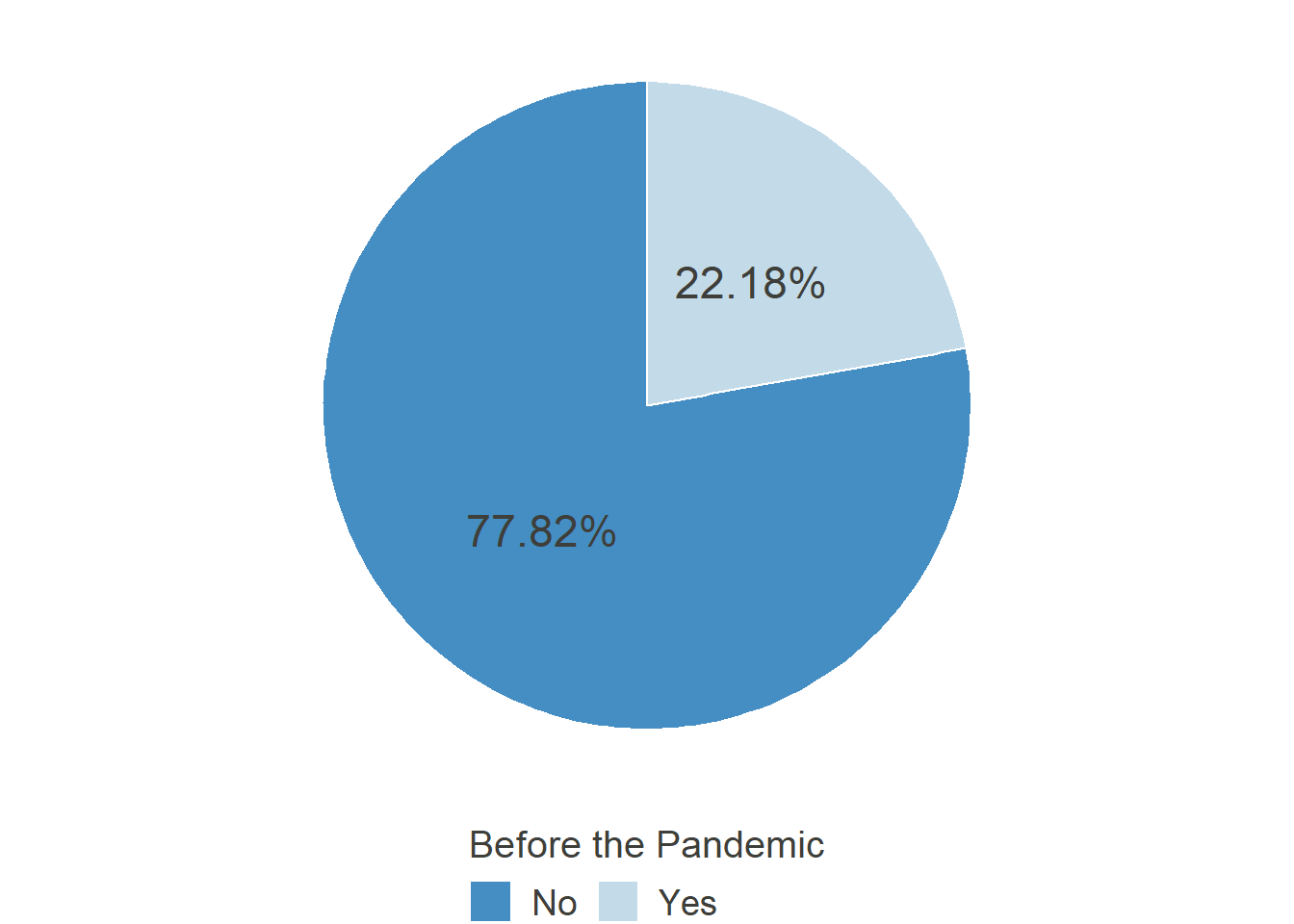
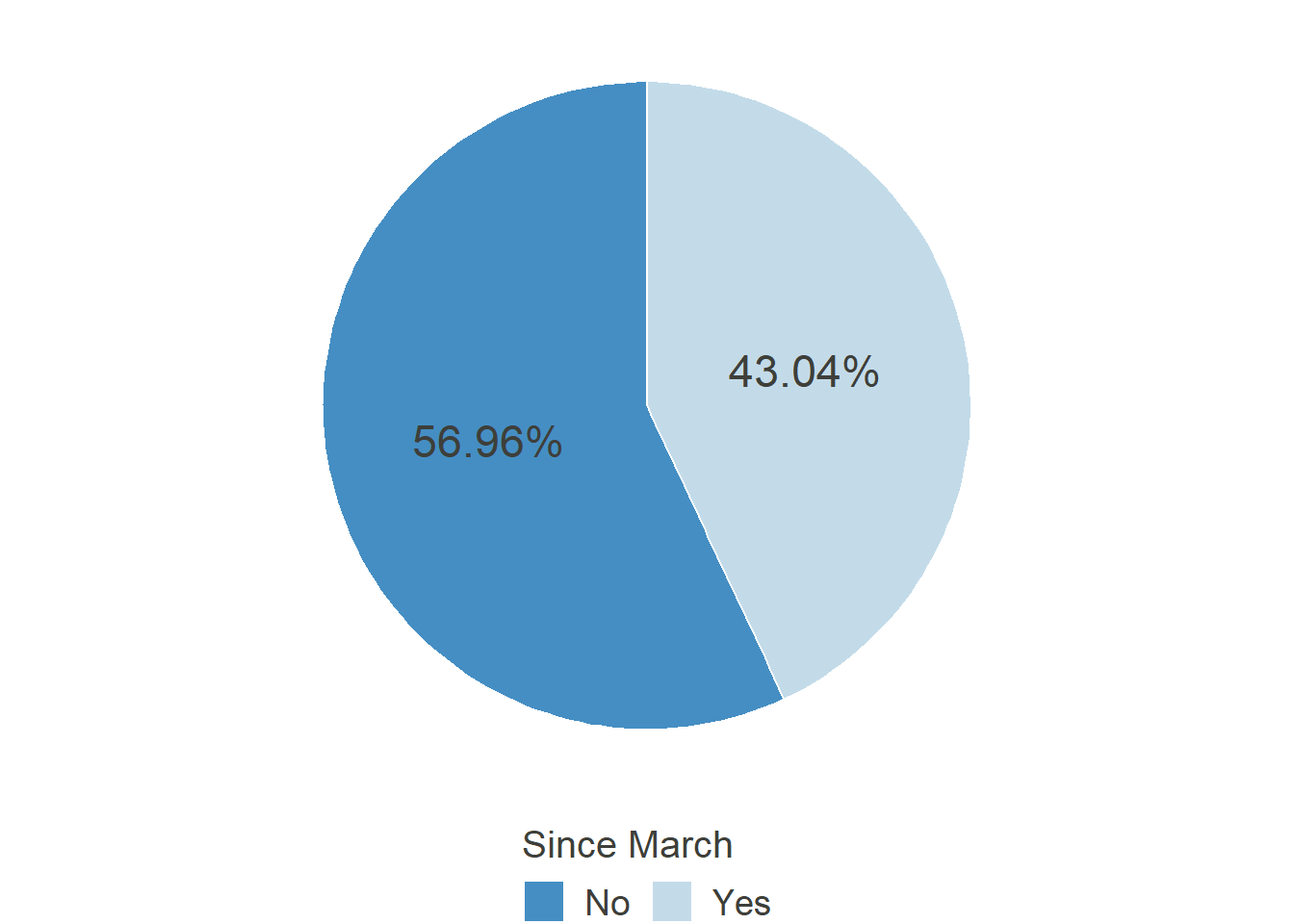
Allowed to work from home
3.1 Permission over Time
Plot
HO_Perm = data_HO[,c("ID",grep("_HO4",names(data_HO), value = T))]
HO_Perm_rel = data.frame(
matrix(
NA,
nrow = length(months_compl),
ncol = 3,
dimnames = list(c(),c("month","perm", "missing"))
)
)
HO_Perm_rel$month = as.factor(months_compl)
for (i in 1:length(months_compl)) {
#means
if (HO_Perm_rel[i,1] %in% months_miss) {
HO_Perm_rel[i,2] = round(prop.table(table(HO_Perm[,paste0("T",i+2,"_HO4")]))[2]*100, digits = 2)
}
}
for (i in 1:length(months_compl)) {
#missing mean
if (HO_Perm_rel[i,1] %in% c("May '20","July '20")) {
HO_Perm_rel[i,3] = HO_Perm_rel[i,2]
} else if (HO_Perm_rel[i,1] == "June '20"){
HO_Perm_rel[i,3] = mean(c(HO_Perm_rel[i-1,2],HO_Perm_rel[i+1,2]))
}
}
HO_Perm_plot = ggplot(HO_Perm_rel, aes(x=month, y = perm)) +
geom_line(aes(group=1, color = "#3182bd"), col= "#3182bd", size = 1.5)+
geom_line(aes(x=month, y=missing, group =1,color = "#3182bd"), col= "#3182bd", size = 1.5, linetype = "dashed" )+
geom_point(col= "#3182bd", size = 3)+
geom_area(aes(group=1), fill="#3182bd", alpha=0.4) +
coord_cartesian(ylim = c(20,60))+
theme_minimal()+
scale_x_discrete(limits = months_compl, name ="" )+
scale_y_continuous(breaks = seq(20,60,10), labels = paste0(seq(20,60,10), "%"), name = "Allowed to work from home")+
labs(caption = "Note: Data was missing for June.")+
theme(axis.text.x = element_text(angle = 45, hjust = 1)) +
font_colour
HO_Perm_plot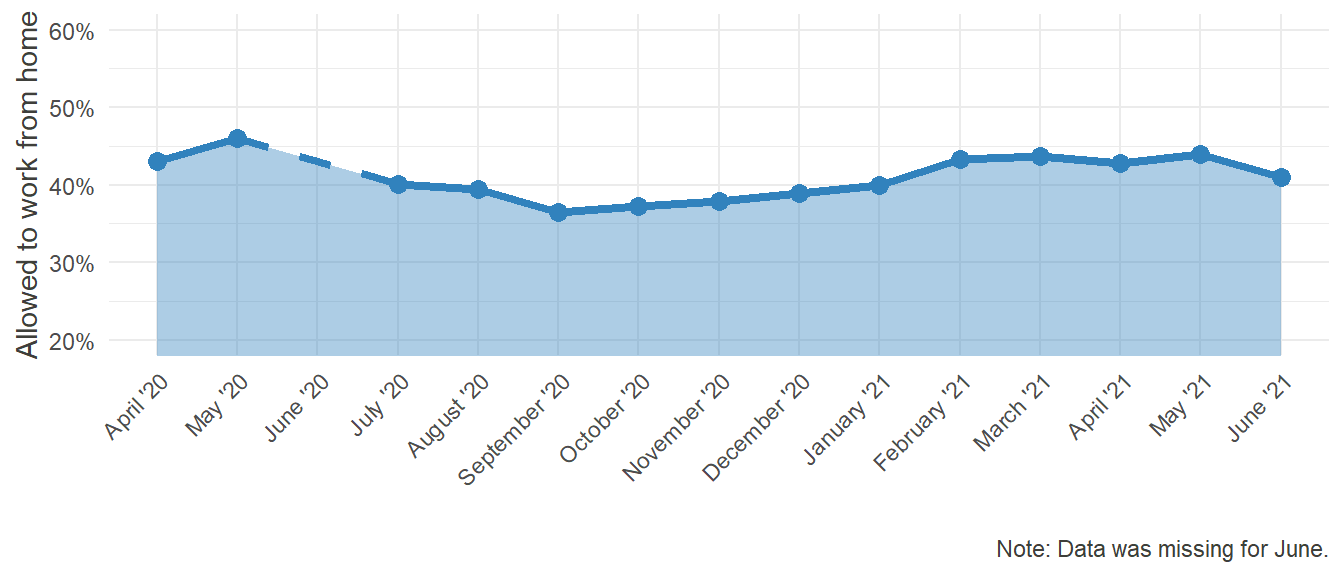
# HO_Perm_rel = data.frame(
# month = as.factor(months_compl),
# perm = round(c(
# (length(which(HO_Perm$T3_HO4 == 2))/length(which((HO_Perm$T3_HO4 != "NA")))),
# (length(which(HO_Perm$T4_HO4 == 2))/length(which((HO_Perm$T4_HO4 != "NA")))),
# NA,
# (length(which(HO_Perm$T6_HO4 == 2))/length(which((HO_Perm$T6_HO4 != "NA")))),
# (length(which(HO_Perm$T7_HO4 == 2))/length(which((HO_Perm$T7_HO4 != "NA")))),
# (length(which(HO_Perm$T8_HO4 == 2))/length(which((HO_Perm$T8_HO4 != "NA")))),
# (length(which(HO_Perm$T9_HO4 == 2))/length(which((HO_Perm$T9_HO4 != "NA")))),
# (length(which(HO_Perm$T10_HO4 == 2))/length(which((HO_Perm$T10_HO4 != "NA")))),
# (length(which(HO_Perm$T11_HO4 == 2))/length(which((HO_Perm$T11_HO4 != "NA")))),
# (length(which(HO_Perm$T12_HO4 == 2))/length(which((HO_Perm$T12_HO4 != "NA"))))
#
# )*100, digits = 2)
# )
#
# # (length(which(HO_Perm$T3_HO4 == 2)) returns the length of the vector of rows, where T3_HO4 is 2 (i.e. those who had permission to work from home). the second term in the division indicates the total amount of responses in the respective month. Rounding all of this after multiplying by 100 for percentages
#
# HO_Perm_rel$missing = c(NA,
# HO_Perm_rel[2,2],
# mean(c(HO_Perm_rel[2,2],HO_Perm_rel[4,2])),
# HO_Perm_rel[4,2],
# NA,
# NA,
# NA,
# NA,
# NA,
# NA)
Additional Information
Since June life in Germany started gradually coming back to a new normality. Businesses were allowed to reopen, albeit under strict regulations and with individual concepts for how to uphold these regulations (so called “hygiene concepts”). Regarding the previous graphs it becomes obvious, that before the pandemic, only few people could work from home, but when it became inevitable, the possibility suddenly emerged in many cases, raising questions about why it was not possible before.
It would be interesting to see, how this general permission fares over time:
## For details on the code for the plots, please change to the "Plots"-Tab and unfold the code there. ##
HO_Perm_plot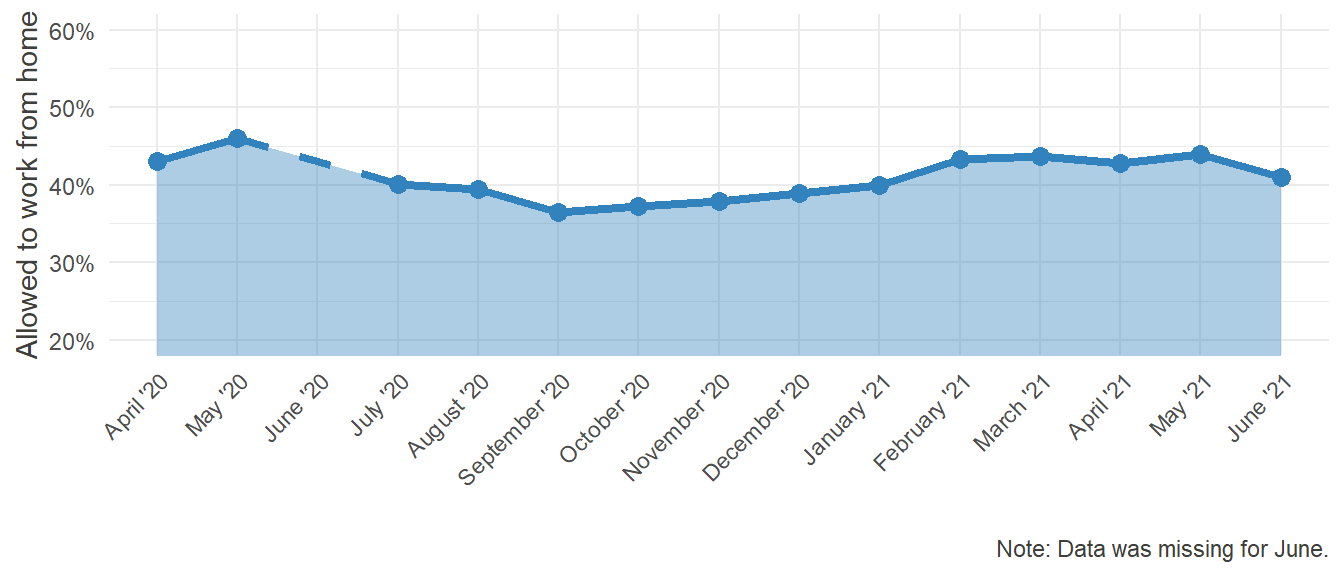
Comparable to the first section of this website, the possibility to work from home peaked in May and steadily declined until September after that, showing that in some cases, the workers were given this permission only as long as it was imperative by law or public pressure. Notably, the level is still far from the 22% it was before the pandemic. Furthermore, there is now a coordinated effort by the German Federal Minister for Labour and Social Affairs Hubertus Heil to pass legislation introducing the “right to Home Office.” Regardless of its success in parliament, it illustrates how the topic of Home Office and the possibility to work there gained traction through the pandemic.
4 Working from Home - but Where?
Plot
# 1 = own, separated Room
# 2 = Designated spot elsewhere
# 3 = Changing places at home depending on the need
# 6 = Other:
# 0 = Missing
HO_loc = data_HO[,grep("_HO18",names(data_HO), value = T )]
HO_loc_prop = data.frame(
matrix(
NA,
ncol = length(months_miss)+1,
nrow = 4,
dimnames = list(c(),c("location", months_miss))
)
)
HO_loc_prop$location = as.factor(c("Own Room","Designated Spot","Changing","Other"))
for (i in 1:(length(months_miss))) {
HO_loc_prop[,i+1] = prop.table(table(HO_loc[HO_loc[,i] >0,i]))
}
HO_loc_prop_long = gather(HO_loc_prop, month, percentage, -location)
HO_loc_prop_long$month = factor(HO_loc_prop_long$month, labels = months_miss)
HO_loc_prop_long$month_rev = factor(HO_loc_prop_long$month, levels = rev(months_miss))
# here we use rev(), so that the plot returns the months from oldest to most recent
HO_loc_prop_long$location_rev = factor(HO_loc_prop_long$location, levels = rev(c("Own Room","Designated Spot","Changing","Other")))
# for better order
# Not much change over Time
HO_loc_plot = ggplot(HO_loc_prop_long, aes(x=percentage, y = month_rev)) +
geom_bar(aes(fill = location_rev), stat = "identity")+
scale_fill_brewer(palette="Blues", direction = 1)+
theme_minimal()+
labs(y="", x = "")+
scale_x_continuous(breaks = seq(0,1,.25), labels = paste0(seq(0,100,25), "%"))+
guides(fill=guide_legend(title="Workplace in the Home Office", title.position = "top", reverse = T))+
theme(legend.position="top")+
font_colour
HO_loc_plot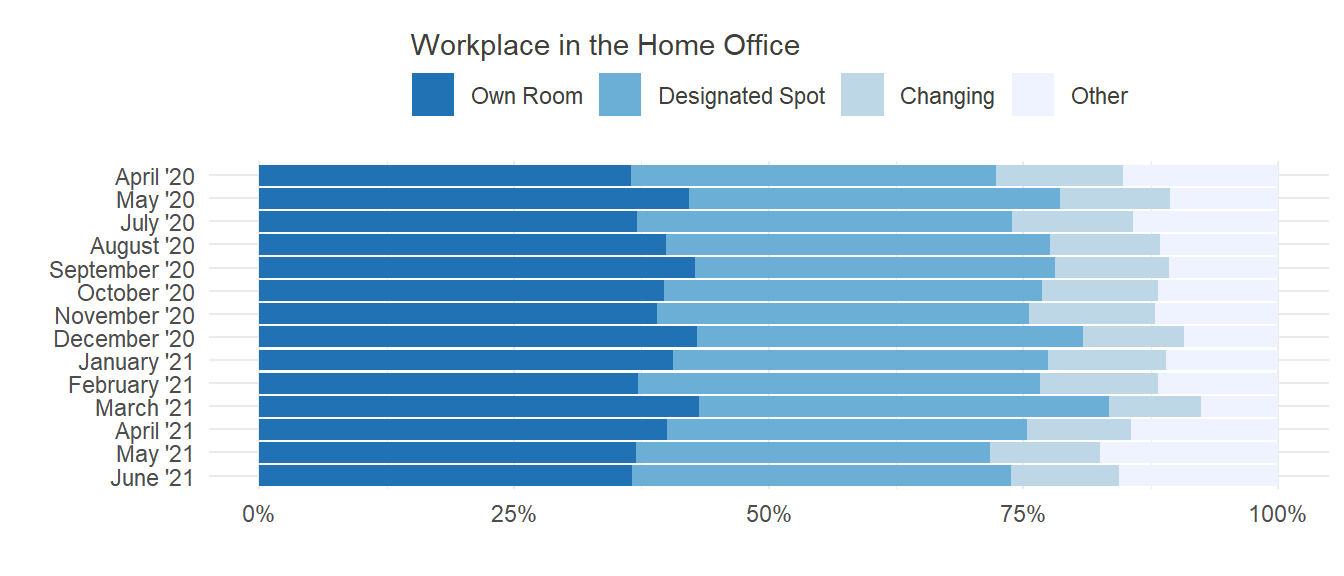
# HO_loc_prop <- data.frame(
# location = c("Own Room","Designated Spot","Changing","Other"),
# April = plyr::count(df = HO_loc, vars = "T3_HO18")[2:5,2]/length(which(HO_loc$T3_HO18 > 0)),
# May = plyr::count(df = HO_loc, vars = "T4_HO18")[2:5,2]/length(which(HO_loc$T4_HO18 > 0)),
# July = plyr::count(df = HO_loc, vars = "T6_HO18")[2:5,2]/length(which(HO_loc$T6_HO18 > 0)),
# August = plyr::count(df = HO_loc, vars = "T7_HO18")[2:5,2]/length(which(HO_loc$T7_HO18 > 0)),
# September = plyr::count(df = HO_loc, vars = "T8_HO18")[2:5,2]/length(which(HO_loc$T8_HO18 > 0)),
# October = plyr::count(df = HO_loc, vars = "T9_HO18")[2:5,2]/length(which(HO_loc$T9_HO18 > 0)),
# November = plyr::count(df = HO_loc, vars = "T10_HO18")[2:5,2]/length(which(HO_loc$T10_HO18 > 0)),
# December = plyr::count(df = HO_loc, vars = "T11_HO18")[2:5,2]/length(which(HO_loc$T11_HO18 > 0)),
# January = plyr::count(df = HO_loc, vars = "T12_HO18")[2:5,2]/length(which(HO_loc$T12_HO18 > 0))
# )
# # this one is a bit complicated :D I wanted to have the proportions of people woking from the respective places.
# # plyr::count(df = HO_loc, vars = "T3_HO18") counts the frequency of every value inside a vector and returns a tibble with two columns (Value and Frequency) per variable. in this case, there are 6 "Values", being 0,1,2,3,6 and NA.
# # by adding [2:5,2] we say that we want only the frequencies (second column) of 1,2,3 and 6 (rows 2:5), since these are the ones that are interesting for us. (see avove)
# # length(which(HO_loc$T3_HO18 > 0)) returns the total of valid responses
Additional Information
Home Office does not equal Home Office. There is a difference in one’s experience when working from home, depending on the locality. Some people have the opportunity of a separate room, which is reserved for work only and has all the needed equipment and supplies, while others might need to improvise a workspace, especially if they never worked from home before. No matter how it is done, there needs to be a separate place at home, where one can and must work. This is important in terms of detachment and productivity. The local separation of work and leisure, typically provided by an outside workplace, helps to separate work and leisure mentally, which in turn increases attention, concentration and motivation.
In our sample, we asked our participants where they worked from when in Home Office. One could expect to see an increase in designated spots as time progresses and people have had the chance to accommodate themselves to working from home. Unfortunately, this trend couldn’t be identified in our data:
## For details on the code for the plots, please change to the "Plots"-Tab and unfold the code there. ##
HO_loc_plot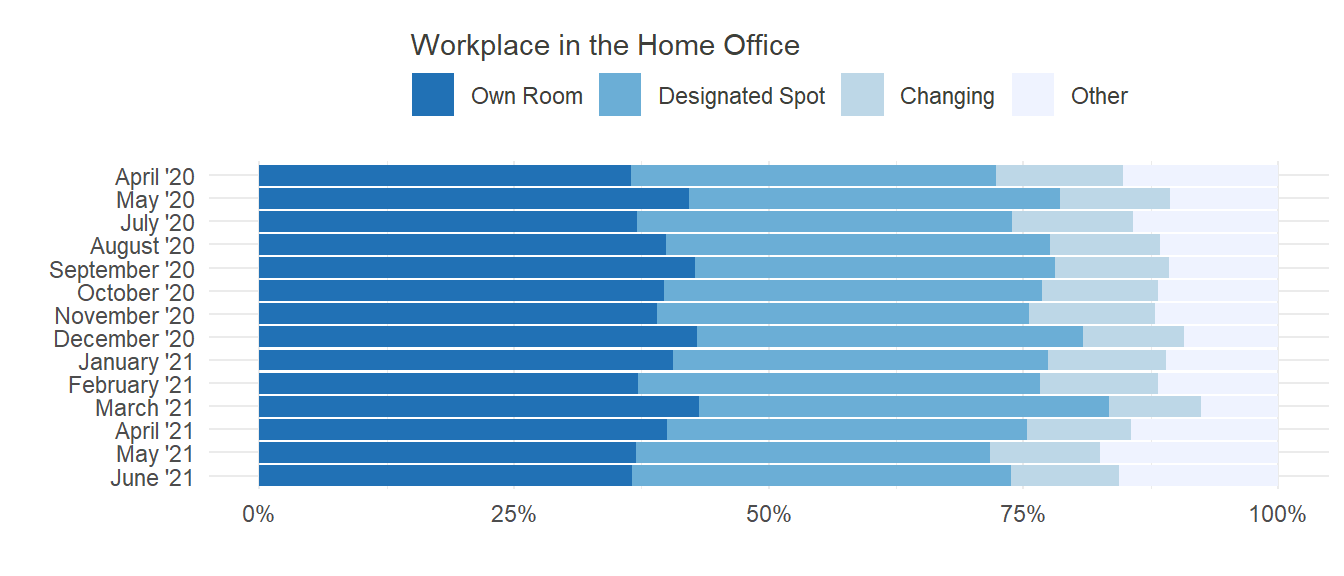
Even though there was no noteworthy change over time, the aspect of locality at home should not be dismissed too early. While further analyses would go beyond the scope of this brief discussion, one could still wonder about possible associated effects. Is there a relationship between place of work and satisfaction? If yes, which one would be the most appropriate? Is a designated spot enough, or does having an own room add incremental gain in satisfaction?
5 Feeling of Isolation
Plot
# HO13 - 16
HO_Isol_Vars = c(grep("_HO13", names(data_HO), value = T), grep("_HO14", names(data_HO), value = T),grep("_HO15", names(data_HO), value = T),grep("_HO16", names(data_HO), value = T))
HO_Isol = data_HO[, c("ID", HO_Isol_Vars)]
# compiling individual means
for (i in 1:length(months_miss)) {
if (i %in% c(1,2)) {
HO_Isol[,paste0("T",i+2,"mean")] = rowMeans(HO_Isol[,grep(paste0("T",i+2,"_HO1"), names(HO_Isol), value = T)])
} else {
HO_Isol[,paste0("T",i+3,"mean")] = rowMeans(HO_Isol[,grep(paste0("T",i+3,"_HO1"), names(HO_Isol), value = T)])
}
}
HO_Isol_means = data.frame(
matrix(
NA,
ncol = 5,
nrow = length(months_compl),
dimnames = list(c(),c("month","means","sd","missing","sd_missing"))
)
)
HO_Isol_means$month = as.factor(months_compl)
for (i in 1:length(months_compl)) {
#means
if (HO_Isol_means[i,1] %in% months_miss) {
HO_Isol_means[i,2] = mean(HO_Isol[,paste0("T",i+2,"mean")], na.rm = T)
}
#sds
if (HO_Isol_means[i,1] %in% months_miss) {
HO_Isol_means[i,3] = sd(HO_Isol[,paste0("T",i+2,"mean")], na.rm = T)
}
}
for (i in 1:length(months_compl)) {
#missing mean
if (HO_Isol_means[i,1] %in% c("May '20","July '20")) {
HO_Isol_means[i,4] = HO_Isol_means[i,2]
} else if (HO_Isol_means[i,1] == "June '20"){
HO_Isol_means[i,4] = mean(c(HO_Isol_means[i-1,2],HO_Isol_means[i+1,2]))
}
#missing sd
if (HO_Isol_means[i,1] %in% c("May '20","July '20")) {
HO_Isol_means[i,5] = HO_Isol_means[i,3]
} else if (HO_Isol_means[i,1] == "June '20"){
HO_Isol_means[i,5] = mean(c(HO_Isol_means[i-1,3],HO_Isol_means[i+1,3]))
}
}
HO_Isol_plot = ggplot(HO_Isol_means, aes(x=month, y = means)) +
geom_line(aes(group=1, color = "#3182bd"), col= "#3182bd", size = 1.5)+
geom_line(aes(x=month, y=missing, group =1,color = "#3182bd"), col= "#3182bd", size = 1.5, linetype = "dashed" )+
geom_point(col= "#3182bd", size = 3)+
geom_ribbon(aes(y=means, ymin = means - (sd/2), ymax = means + (sd/2), group = 1),fill="#3182bd", alpha=0.4) +
geom_ribbon(aes(y=missing, ymin = missing - (sd_missing/2), ymax = missing + (sd_missing/2), group = 1),fill="#3182bd", alpha=0.3) +
theme_minimal()+
coord_cartesian(ylim = c(1,3))+
scale_x_discrete(limits = months_compl, name ="" )+
scale_y_continuous(breaks = seq(1.5,3,0.5), name = "Feeling of Isolation")+
labs(caption = "Note: Data was missing for June. Ribbon represents 1SD around the mean.")+
theme(axis.text.x = element_text(angle = 45, hjust = 1)) +
font_colour
HO_Isol_plot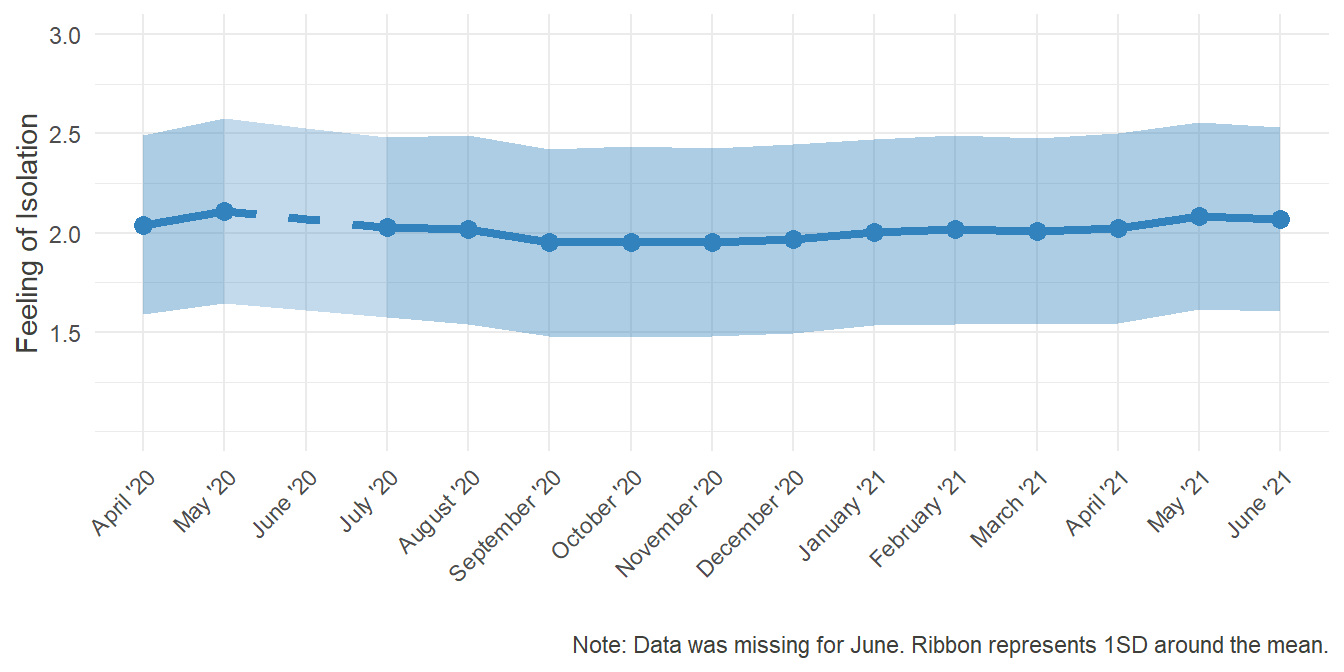
HO_Isol = cbind(HO_Isol, HO_Perc)
#adding percentage of time worked in Home Office for Correlation seen in the text below
HO_Isol_Perc_Cor = c(1:length(months_miss))
HO_Isol_Perc_Cor[] = NA
for (i in 1:length(months_miss)) {
if (i < 3) {
HO_Isol_Perc_Cor[i] = cor(HO_Isol[,paste0("T",i+2,"mean")], HO_Isol[,paste0("T",i+2,"_HO6")], use = "complete.obs")
} else {
HO_Isol_Perc_Cor[i] = cor(HO_Isol[,paste0("T",i+3,"mean")], HO_Isol[,paste0("T",i+3,"_HO6")], use = "complete.obs")
}
}
mean_r =round(mean(HO_Isol_Perc_Cor), digits = 2)
# HO_Isol$T3mean = rowMeans(HO_Isol[,grep("T3_HO1", names(HO_Isol), value = T)])
# HO_Isol$T4mean = rowMeans(HO_Isol[,grep("T4_HO1", names(HO_Isol), value = T)])
# HO_Isol$T6mean = rowMeans(HO_Isol[,grep("T6_HO1", names(HO_Isol), value = T)])
# HO_Isol$T7mean = rowMeans(HO_Isol[,grep("T7_HO1", names(HO_Isol), value = T)])
# HO_Isol$T8mean = rowMeans(HO_Isol[,grep("T8_HO1", names(HO_Isol), value = T)])
# HO_Isol$T9mean = rowMeans(HO_Isol[,grep("T9_HO1", names(HO_Isol), value = T)])
# HO_Isol$T10mean = rowMeans(HO_Isol[,grep("T10_HO1", names(HO_Isol), value = T)])
# HO_Isol$T11mean = rowMeans(HO_Isol[,grep("T11_HO1", names(HO_Isol), value = T)])
# HO_Isol$T12mean = rowMeans(HO_Isol[,grep("T12_HO1", names(HO_Isol), value = T)])
# # Compiling the respective individual means of Isolation at every datapoint (dyplr might have given an easyer way)
# HO_Isol_means = data.frame(
# month = as.factor(months_compl),
# means = c(
# mean(HO_Isol$T3mean, na.rm = T),
# mean(HO_Isol$T4mean, na.rm = T),
# NA,
# mean(HO_Isol$T6mean, na.rm = T),
# mean(HO_Isol$T7mean, na.rm = T),
# mean(HO_Isol$T8mean, na.rm = T),
# mean(HO_Isol$T9mean, na.rm = T),
# mean(HO_Isol$T10mean, na.rm = T),
# mean(HO_Isol$T11mean, na.rm = T),
# mean(HO_Isol$T12mean, na.rm = T)
# ),
# missing = c(
# NA,
# mean(HO_Isol$T4mean, na.rm = T),
# mean(c(mean(HO_Isol$T4mean, na.rm = T),mean(HO_Isol$T6mean, na.rm = T))),
# mean(HO_Isol$T6mean, na.rm = T),
# NA,
# NA,
# NA,
# NA,
# NA,
# NA
# ),
# sd = c(
# sd(HO_Isol$T3mean, na.rm = T),
# sd(HO_Isol$T4mean, na.rm = T),
# NA,
# sd(HO_Isol$T6mean, na.rm = T),
# sd(HO_Isol$T7mean, na.rm = T),
# sd(HO_Isol$T8mean, na.rm = T),
# sd(HO_Isol$T9mean, na.rm = T),
# sd(HO_Isol$T10mean, na.rm = T),
# sd(HO_Isol$T11mean, na.rm = T),
# sd(HO_Isol$T12mean, na.rm = T)
# ),
# sd_missing = c(
# NA,
# sd(HO_Isol$T4mean, na.rm = T),
# mean(c(sd(HO_Isol$T4mean, na.rm = T), sd(HO_Isol$T6mean, na.rm = T))),
# sd(HO_Isol$T6mean, na.rm = T),
# NA,
# NA,
# NA,
# NA,
# NA,
# NA
# )
#
# )
#
# mean_r = round(mean(c(
# cor(HO_Isol[,"T3mean"], HO_Isol[,"T3_HO6"], use = "complete.obs"),
# cor(HO_Isol[,"T4mean"], HO_Isol[,"T4_HO6"], use = "complete.obs"),
# cor(HO_Isol[,"T6mean"], HO_Isol[,"T6_HO6"], use = "complete.obs"),
# cor(HO_Isol[,"T7mean"], HO_Isol[,"T7_HO6"], use = "complete.obs"),
# cor(HO_Isol[,"T8mean"], HO_Isol[,"T8_HO6"], use = "complete.obs"),
# cor(HO_Isol[,"T9mean"], HO_Isol[,"T9_HO6"], use = "complete.obs"),
# cor(HO_Isol[,"T10mean"], HO_Isol[,"T10_HO6"], use = "complete.obs"),
# cor(HO_Isol[,"T11mean"], HO_Isol[,"T11_HO6"], use = "complete.obs"),
# cor(HO_Isol[,"T12mean"], HO_Isol[,"T12_HO6"], use = "complete.obs")
# )), digits = 2)
Additional Information
In most cases, working is a social process and the workplace is an inherently social space. Regular meetings, quick coordination of further steps, running into each other in the hallways, eating lunch together, sharing personal stories and experiences, and so on. All of that was not possible in the same manner when a portion of the workforce was forced to work from home only.
In the field of telework and telecommuting, the concept of Professional Isolation emerged, being defined as “a state of mind or belief that one is out of touch with others in the workplace” (Golden et al., 2008) (Golden et al., 2008). This isn’t necessarily bound to happen when people work from home. In its core, it is a feeling of not being involved in the essential professional networks, which can also occur while sitting in a regular office. Nonetheless there is a tendency among teleworkers to lack social comparison of their performance and more complex contextual clues about their workplace.
In line of this research, we measured professional isolation by having people rate, for example:
“I feel left out on activities and meetings that could enhance my career”
“I miss informal interaction with others.”
## For details on the code for the plots, please change to the "Plots"-Tab and unfold the code there. ##
HO_Isol_plot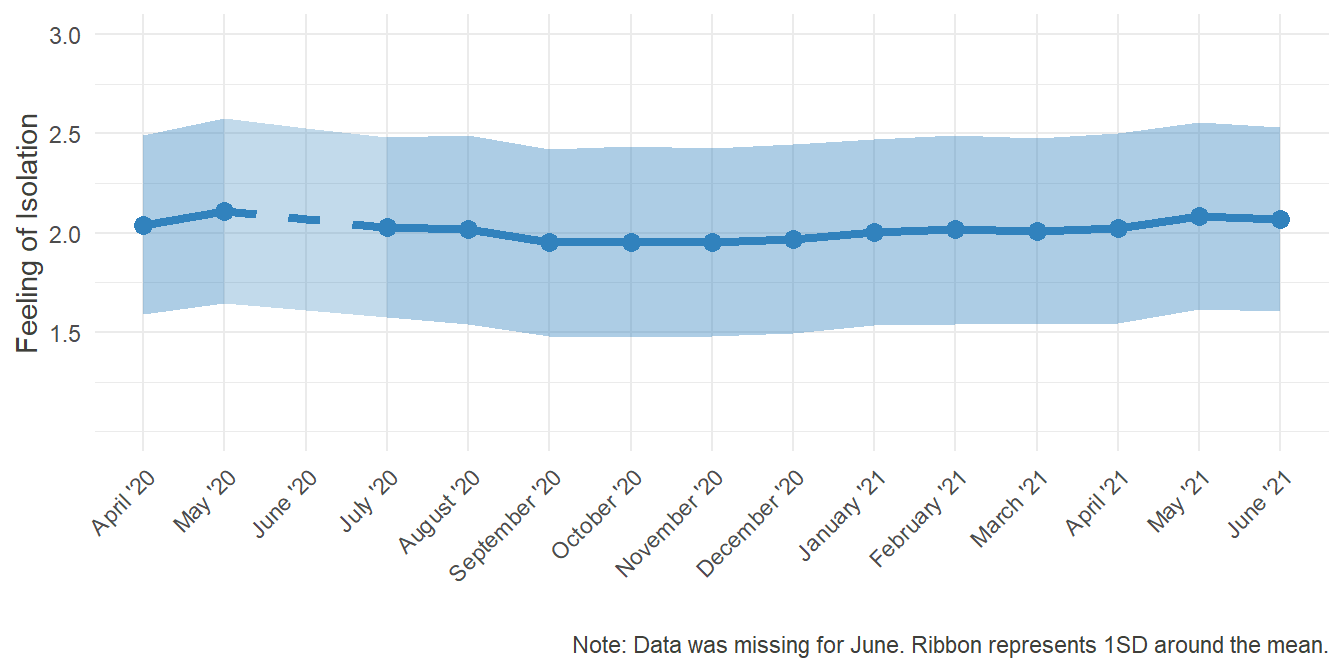 Regarding the fact, that the response Scale ranged from 1 - Never to 5 - Very often, this level of average Isolation is rather surprising. Apparently, feeling out of the loop and missing the informal conversation with colleagues wasn’t as much of an issue.
Regarding the fact, that the response Scale ranged from 1 - Never to 5 - Very often, this level of average Isolation is rather surprising. Apparently, feeling out of the loop and missing the informal conversation with colleagues wasn’t as much of an issue.
The potential reasons for that can be manyfold. Maybe the communication through digital media was sufficient to replace real meetings. Or maybe the data isn’t representative, as not that many people indicated working from home entirely.
Investigating a smaller subset of participants, the ones who spent most of their worktime in Home Office, could yield different results. The mean correlation of 0.23 between the percentage of time spent in Home Office and feeling of professional isolation serves as further evidence of this possibility, as it shows that the more one works from home, the more he or she tends to feel isolated.
6 Satisfaction with Home Office
6.1 Overall Development over Time
Plot
# HO31 = Satisfaction
# HO32 = Efficacy
# HO3 = Equipment (1=No, 2=Yes)
# covid11 = Childcare (2 = Emergency Care, 3 = I cared at home, 4 = My Partner cared at home, 5 = other family members/friends, 6 = other)
Sat_variables = c(grep("_HO3",names(data_HO), value = T),grep("_covid11",names(data_HO), value = T), "ID")
HO_Sat = data_HO[,Sat_variables]
HO_Sat = HO_Sat[,-which(names(HO_Sat) %in% grep("_HO30",names(HO_Sat), value = T))]
# since grep("_HO3",names(data_HO), value = T) returns all the names with _H03 in them, and we don't need HO30, this line above removes all the Tx_HO30 from the dataframe
# Satisfaction (_HO31) was measured on a scale of 1-5, but there are Missings in the form of zeroes. So in order to avoid a distortion of the mean, we only use the rows, where the value is greater than 0
HO_Sat_means = data.frame(
matrix(
NA,
ncol = 9,
nrow = length(months_compl),
dimnames = list(c(),c("month","means","sd","missing","mis_sd","means_care_self","means_care_partner", "missing_self", "missing_partner"))
)
)
HO_Sat_means$month = as.factor(months_compl)
for (i in 1:length(months_compl)) {
#means
if (HO_Sat_means[i,1] %in% months_miss) {
HO_Sat_means[i,2] = mean(HO_Sat[HO_Sat[,paste0("T",i+2,"_HO31")]>0,paste0("T",i+2,"_HO31")], na.rm = T)
}
#sds
if (HO_Sat_means[i,1] %in% months_miss) {
HO_Sat_means[i,3] = sd(HO_Sat[HO_Sat[,paste0("T",i+2,"_HO31")]>0,paste0("T",i+2,"_HO31")], na.rm = T)
}
}
for (i in 1:length(months_compl)) {
#missing mean
if (HO_Sat_means[i,1] %in% c("May '20","July '20")) {
HO_Sat_means[i,4] = HO_Sat_means[i,2]
} else if (HO_Sat_means[i,1] == "June '20"){
HO_Sat_means[i,4] = mean(c(HO_Sat_means[i-1,2],HO_Sat_means[i+1,2]))
}
#missing sd
if (HO_Sat_means[i,1] %in% c("May '20","July '20")) {
HO_Sat_means[i,5] = HO_Sat_means[i,3]
} else if (HO_Sat_means[i,1] == "June '20"){
HO_Sat_means[i,5] = mean(c(HO_Sat_means[i-1,3],HO_Sat_means[i+1,3]))
}
}
HO_Sat_plot = ggplot(HO_Sat_means, aes(x=month, y = means)) +
geom_line(aes(group=1, color = "#3182bd"), col= "#3182bd", size = 1.5)+
geom_line(aes(x=month, y=missing, group =1,color = "#3182bd"), col= "#3182bd", size = 1.5, linetype = "dashed" )+
geom_point(col= "#3182bd", size = 3)+
geom_ribbon(aes(y=means, ymin = means - (sd/2), ymax = means + (sd/2), group = 1),fill="#3182bd", alpha=0.4) +
geom_ribbon(aes(y=missing, ymin = missing - (mis_sd/2), ymax = missing + (mis_sd/2), group = 1),fill="#3182bd", alpha=0.3) +
theme_minimal()+
coord_cartesian(ylim = c(1,5))+
scale_x_discrete(limits = months_compl, name ="" )+
scale_y_continuous(breaks = seq(1,5,1), name = "Satisfaction with Home Office")+
labs(caption = "Note: Data was missing for June. Ribbon represents 1SD around the mean.")+
theme(axis.text.x = element_text(angle = 45, hjust = 1))+
font_colour
HO_Sat_plot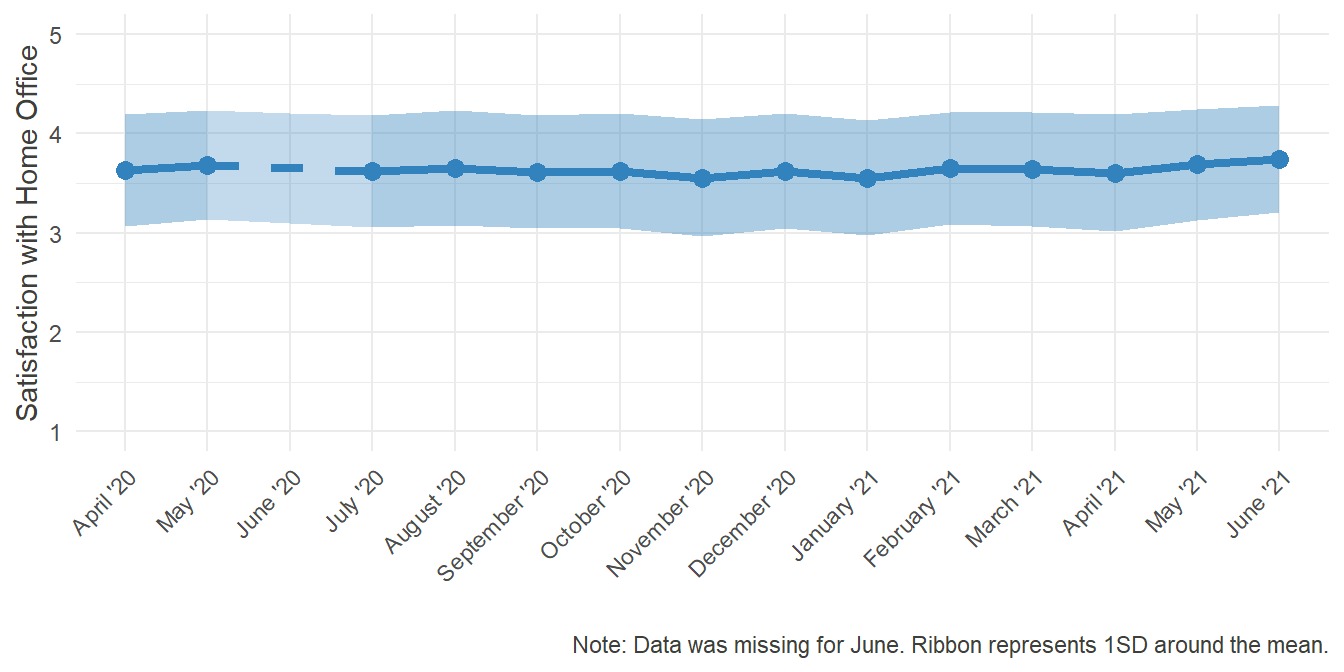
# Old Code
# HO_Sat_means = data.frame(
# month = as.factor(months_compl[1:10]),
# means = c(
# mean(HO_Sat[HO_Sat$T3_HO31>0,"T3_HO31"], na.rm = T),
# mean(HO_Sat[HO_Sat$T4_HO31>0,"T4_HO31"], na.rm = T),
# NA,
# mean(HO_Sat[HO_Sat$T6_HO31>0,"T6_HO31"], na.rm = T),
# mean(HO_Sat[HO_Sat$T7_HO31>0,"T7_HO31"], na.rm = T),
# mean(HO_Sat[HO_Sat$T8_HO31>0,"T8_HO31"], na.rm = T),
# mean(HO_Sat[HO_Sat$T9_HO31>0,"T9_HO31"], na.rm = T),
# mean(HO_Sat[HO_Sat$T10_HO31>0,"T10_HO31"], na.rm = T),
# mean(HO_Sat[HO_Sat$T11_HO31>0,"T11_HO31"], na.rm = T),
# mean(HO_Sat[HO_Sat$T12_HO31>0,"T12_HO31"], na.rm = T)
# ),
# sd = c(
# sd(HO_Sat[HO_Sat$T3_HO31>0,"T3_HO31"], na.rm = T),
# sd(HO_Sat[HO_Sat$T4_HO31>0,"T4_HO31"], na.rm = T),
# NA,
# sd(HO_Sat[HO_Sat$T6_HO31>0,"T6_HO31"], na.rm = T),
# sd(HO_Sat[HO_Sat$T7_HO31>0,"T7_HO31"], na.rm = T),
# sd(HO_Sat[HO_Sat$T8_HO31>0,"T8_HO31"], na.rm = T),
# sd(HO_Sat[HO_Sat$T9_HO31>0,"T9_HO31"], na.rm = T),
# sd(HO_Sat[HO_Sat$T10_HO31>0,"T10_HO31"], na.rm = T),
# sd(HO_Sat[HO_Sat$T11_HO31>0,"T11_HO31"], na.rm = T),
# sd(HO_Sat[HO_Sat$T12_HO31>0,"T12_HO31"], na.rm = T)
# ),
# missing = c(
# NA,
# mean(HO_Sat[HO_Sat$T4_HO31>0,"T4_HO31"], na.rm = T),
# mean(c(mean(HO_Sat[HO_Sat$T4_HO31>0,"T4_HO31"], na.rm = T),mean(HO_Sat[HO_Sat$T6_HO31>0,"T6_HO31"], na.rm = T))),
# mean(HO_Sat[HO_Sat$T6_HO31>0,"T6_HO31"], na.rm = T),
# NA,
# NA,
# NA,
# NA,
# NA,
# NA
# ),
# mis_sd = c(
# NA,
# sd(HO_Sat[HO_Sat$T4_HO31>0,"T4_HO31"], na.rm = T),
# mean(c(sd(HO_Sat[HO_Sat$T4_HO31>0,"T4_HO31"], na.rm = T),sd(HO_Sat[HO_Sat$T6_HO31>0,"T6_HO31"], na.rm = T))),
# sd(HO_Sat[HO_Sat$T6_HO31>0,"T6_HO31"], na.rm = T),
# NA,
# NA,
# NA,
# NA,
# NA,
# NA
# )
# )Additional Information
At the end of the day, one of the most important lesson to draw from this pandemic regarding Home Office would be how to make working from home as satisfactory as possible. To be able to draw conclusions from this data, it is necessary to first get an overall view of the satisfaction experienced when it comes to working from home, and subsequently look at potential correlates and causes.
## For details on the code for the plots, please change to the "Plots"-Tab and unfold the code there. ##
HO_Sat_plot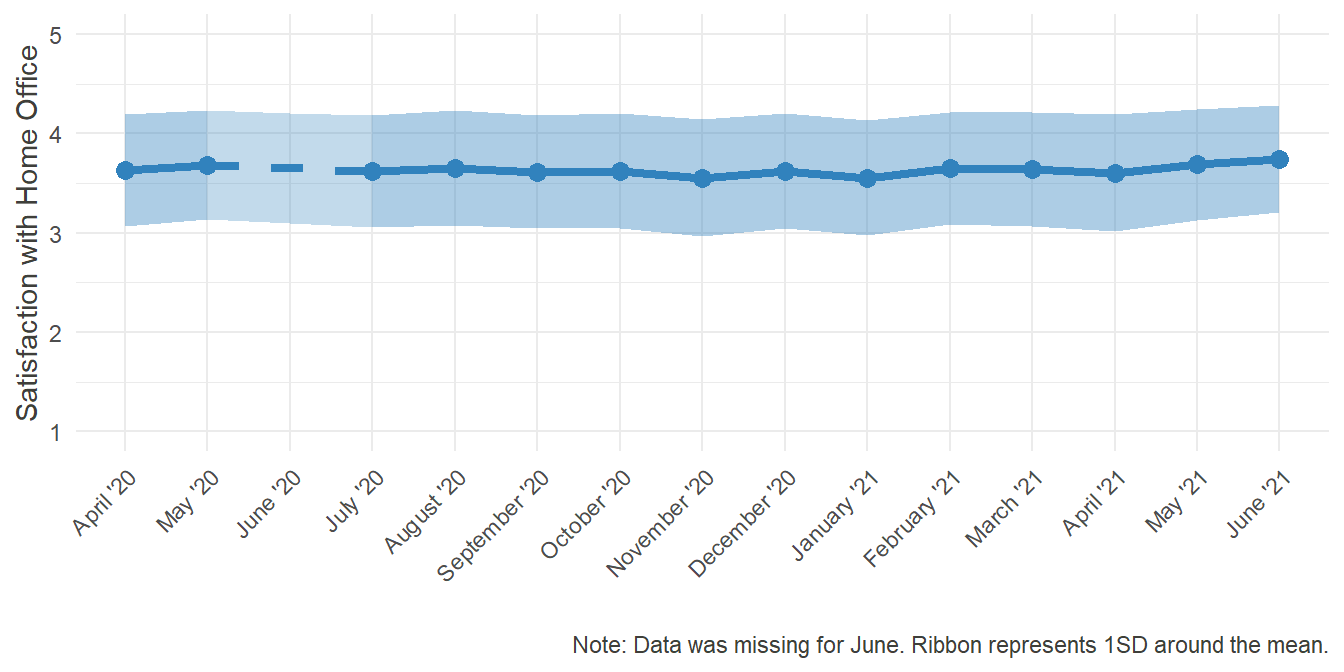
Satisfaction was consistently above the average of 3, indicating that most people were rather happy with their overall experience in Home Office.
Now that in and of itself is good news. Even though the all-encompassing situation was rather grim, people apparently were more or less happy with their work from home. The interesting point now is to find out, what caused this satisfaction, so that we can learn how to improve the experience for others.
6.2 Child Care
Plot
# Here we use the syntax of dplyr. We add a column with the means of "satisfaction" by group (Childcare provided by oneself, covid11 == 3, or by the partner, covid11 == 4) by using the "mutate" function: creating a vector called means_care_..., filling it with the conditional means, and adding it to the existing dataframe.
for (i in 1:length(months_compl)) {
#means for childcare provided by oneself
if (HO_Sat_means[i,1] %in% months_miss) {
HO_Sat_means[i,6] = mean(
HO_Sat[
(HO_Sat[,paste0("T",i+2,"_HO31")]>0 & HO_Sat[,paste0("T",i+2,"_covid11")]==3),
paste0("T",i+2,"_HO31")],
na.rm = T
)
# Means for childcare provided by partner
HO_Sat_means[i,7] = mean(
HO_Sat[
(HO_Sat[,paste0("T",i+2,"_HO31")]>0 & HO_Sat[,paste0("T",i+2,"_covid11")]==4),
paste0("T",i+2,"_HO31")],
na.rm = T
)
}
}
for (i in 1:length(months_compl)) {
if (HO_Sat_means[i,1] %in% c("May '20","July '20")) {
#missing mean self
HO_Sat_means[i,8] = HO_Sat_means[i,6]
#missing mean partner
HO_Sat_means[i,9] = HO_Sat_means[i,7]
} else if (HO_Sat_means[i,1] == "June '20"){
#missing mean self
HO_Sat_means[i,8] = mean(c(HO_Sat_means[i-1,6],HO_Sat_means[i+1,6]))
#missing mean partner
HO_Sat_means[i,9] = mean(c(HO_Sat_means[i-1,7],HO_Sat_means[i+1,7]))
}
}
colors = c("oneself" = "#e6550d", "partner" = "#31a354")
# this is for the subsequent plot, in Order to have a legend with custom labels
HO_Sat_care_plot = ggplot(HO_Sat_means, aes(x=month, y = means)) +
geom_line(aes(group=1, color = "#3182bd"),col = "#3182bd", size = 1, linetype = "twodash")+
geom_line(aes(x=month, y=missing, group =1,color = "#3182bd"), col = "#3182bd", size = 1, linetype = "dashed" )+
geom_point(color= "#3182bd", size = 1.5)+
geom_ribbon(aes(y=means, ymin = means - (sd/2), ymax = means + (sd/2), group = 1),fill="#3182bd", alpha=0.4) +
geom_ribbon(aes(y=missing, ymin = missing - (mis_sd/2), ymax = missing + (mis_sd/2), group = 1),fill="#3182bd", alpha=0.3) +
theme_minimal()+
coord_cartesian(ylim = c(1,5))+
scale_x_discrete(limits = months_compl, name ="" )+
scale_y_continuous(breaks = seq(1,5,1), name = "Satisfaction with Home Office")+
labs(caption = "Note: Data was missing for June. Ribbon represents 1SD around the mean.", color = "Childcare provided by...")+
# up until now, same graph as before. Adding the conditional lines:
geom_line(aes(x=month, y= means_care_self, group=1, color="oneself"), size = 1.5 )+
geom_line(aes(x=month, y=missing_self, group =1,color = "oneself"), size = 1.5, linetype = "dashed" )+
geom_point(aes(x=month, y = means_care_self, color = "oneself"), size = 3)+
geom_line(aes(x=month, y= means_care_partner, group=1, color="partner"), size = 1.5 )+
geom_line(aes(x=month, y=missing_partner, group =1,color = "partner"), size = 1.5, linetype = "dashed" )+
geom_point(aes(x=month, y = means_care_partner, color = "partner"), size = 3)+
#we defined the colors above, so we can use color = "oneself"/"partner"
scale_color_manual(values = colors)+
# Here we tell the legend, how it should call its values, using the vector from above
theme(legend.position = "top")+
theme(axis.text.x = element_text(angle = 45, hjust = 1))+
font_colour
HO_Sat_care_plot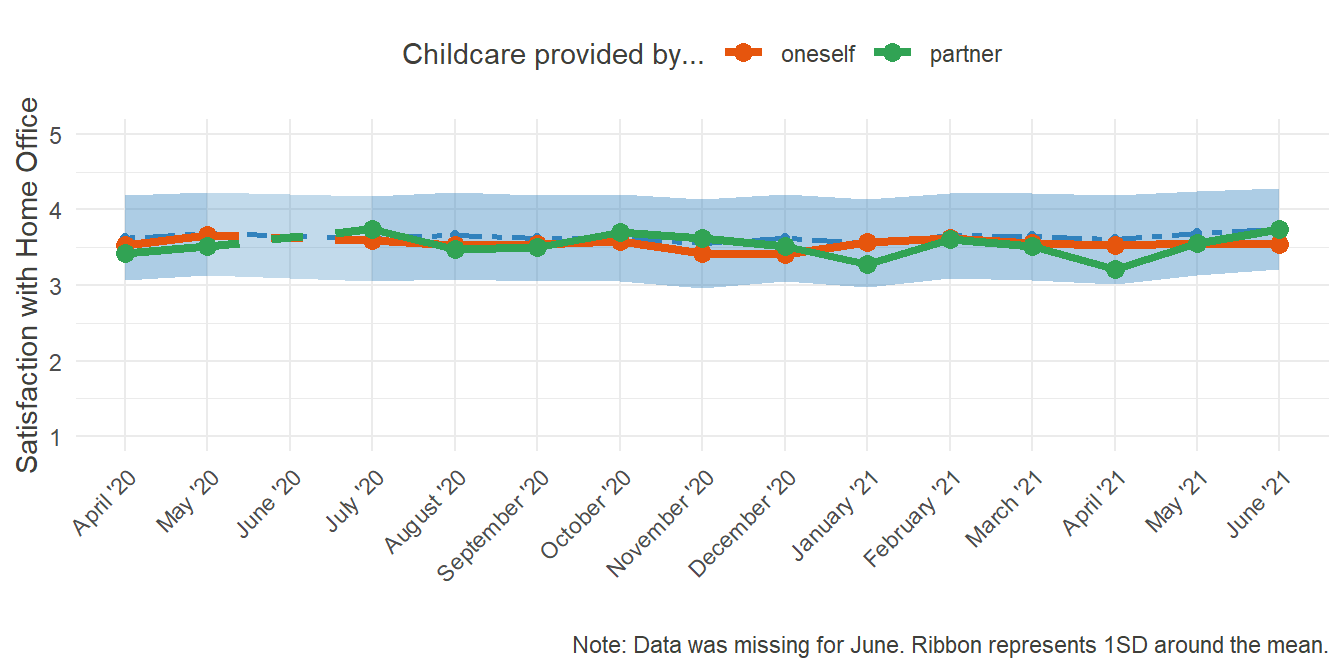
# Old code
# HO_Sat_means = HO_Sat_means %>%
# mutate(means_care_self = c(
# mean(HO_Sat[(HO_Sat$T3_covid11 == 3 & HO_Sat$T3_HO31>0), "T3_HO31"], na.rm = T),
# mean(HO_Sat[(HO_Sat$T4_covid11 == 3 & HO_Sat$T4_HO31>0), "T4_HO31"], na.rm = T),
# NA,
# mean(HO_Sat[(HO_Sat$T6_covid11 == 3 & HO_Sat$T6_HO31>0), "T6_HO31"], na.rm = T),
# mean(HO_Sat[(HO_Sat$T7_covid11 == 3 & HO_Sat$T7_HO31>0), "T7_HO31"], na.rm = T),
# mean(HO_Sat[(HO_Sat$T8_covid11 == 3 & HO_Sat$T8_HO31>0), "T8_HO31"], na.rm = T),
# mean(HO_Sat[(HO_Sat$T9_covid11 == 3 & HO_Sat$T9_HO31>0), "T9_HO31"], na.rm = T),
# mean(HO_Sat[(HO_Sat$T10_covid11 == 3 & HO_Sat$T10_HO31>0), "T10_HO31"], na.rm = T),
# mean(HO_Sat[(HO_Sat$T11_covid11 == 3 & HO_Sat$T11_HO31>0), "T11_HO31"], na.rm = T),
# mean(HO_Sat[(HO_Sat$T12_covid11 == 3 & HO_Sat$T12_HO31>0), "T12_HO31"], na.rm = T)
# ))%>%
# mutate(means_care_partner = c(
# mean(HO_Sat[(HO_Sat$T3_covid11 == 4 & HO_Sat$T3_HO31>0), "T3_HO31"], na.rm = T),
# mean(HO_Sat[(HO_Sat$T4_covid11 == 4 & HO_Sat$T4_HO31>0), "T4_HO31"], na.rm = T),
# NA,
# mean(HO_Sat[(HO_Sat$T6_covid11 == 4 & HO_Sat$T6_HO31>0), "T6_HO31"], na.rm = T),
# mean(HO_Sat[(HO_Sat$T7_covid11 == 4 & HO_Sat$T7_HO31>0), "T7_HO31"], na.rm = T),
# mean(HO_Sat[(HO_Sat$T8_covid11 == 4 & HO_Sat$T8_HO31>0), "T8_HO31"], na.rm = T),
# mean(HO_Sat[(HO_Sat$T9_covid11 == 4 & HO_Sat$T9_HO31>0), "T9_HO31"], na.rm = T),
# mean(HO_Sat[(HO_Sat$T10_covid11 == 4 & HO_Sat$T10_HO31>0), "T10_HO31"], na.rm = T),
# mean(HO_Sat[(HO_Sat$T11_covid11 == 4 & HO_Sat$T11_HO31>0), "T11_HO31"], na.rm = T),
# mean(HO_Sat[(HO_Sat$T12_covid11 == 4 & HO_Sat$T12_HO31>0), "T12_HO31"], na.rm = T)
# ))%>%
# mutate(missing_self = c(
# NA,
# mean(HO_Sat[(HO_Sat$T4_covid11 == 3 & HO_Sat$T4_HO31>0), "T4_HO31"], na.rm = T),
# mean(c( mean(HO_Sat[(HO_Sat$T4_covid11 == 3 & HO_Sat$T4_HO31>0), "T4_HO31"], na.rm = T),mean(HO_Sat[(HO_Sat$T6_covid11 == 3 & HO_Sat$T6_HO31>0), "T6_HO31"], na.rm = T))),
# mean(HO_Sat[(HO_Sat$T6_covid11 == 3 & HO_Sat$T6_HO31>0), "T6_HO31"], na.rm = T),
# NA,
# NA,
# NA,
# NA,
# NA,
# NA
# ))%>%
# mutate(missing_partner = c(
# NA,
# mean(HO_Sat[(HO_Sat$T4_covid11 == 4 & HO_Sat$T4_HO31>0), "T4_HO31"], na.rm = T),
# mean(c( mean(HO_Sat[(HO_Sat$T4_covid11 == 4 & HO_Sat$T4_HO31>0), "T4_HO31"], na.rm = T),mean(HO_Sat[(HO_Sat$T6_covid11 == 4 & HO_Sat$T6_HO31>0), "T6_HO31"], na.rm = T))),
# mean(HO_Sat[(HO_Sat$T6_covid11 == 4 & HO_Sat$T6_HO31>0), "T6_HO31"], na.rm = T),
# NA,
# NA,
# NA,
# NA,
# NA,
# NA
# ))
Additional Information
One factor that could hold influence is higher demand at work, like is generally theorized in the Work-Demands-Resources-Model. One such demand could be the additional workload of caring for children, since kindergartens and schools were closed also and only in extreme cases parents could get “emergency childcare.” So, let us compare the situation of those, who had to care for their children by themselves with those, whose partners took on the task of caring for their children.
## For details on the code for the plots, please change to the "Plots"-Tab and unfold the code there. ##
HO_Sat_care_plot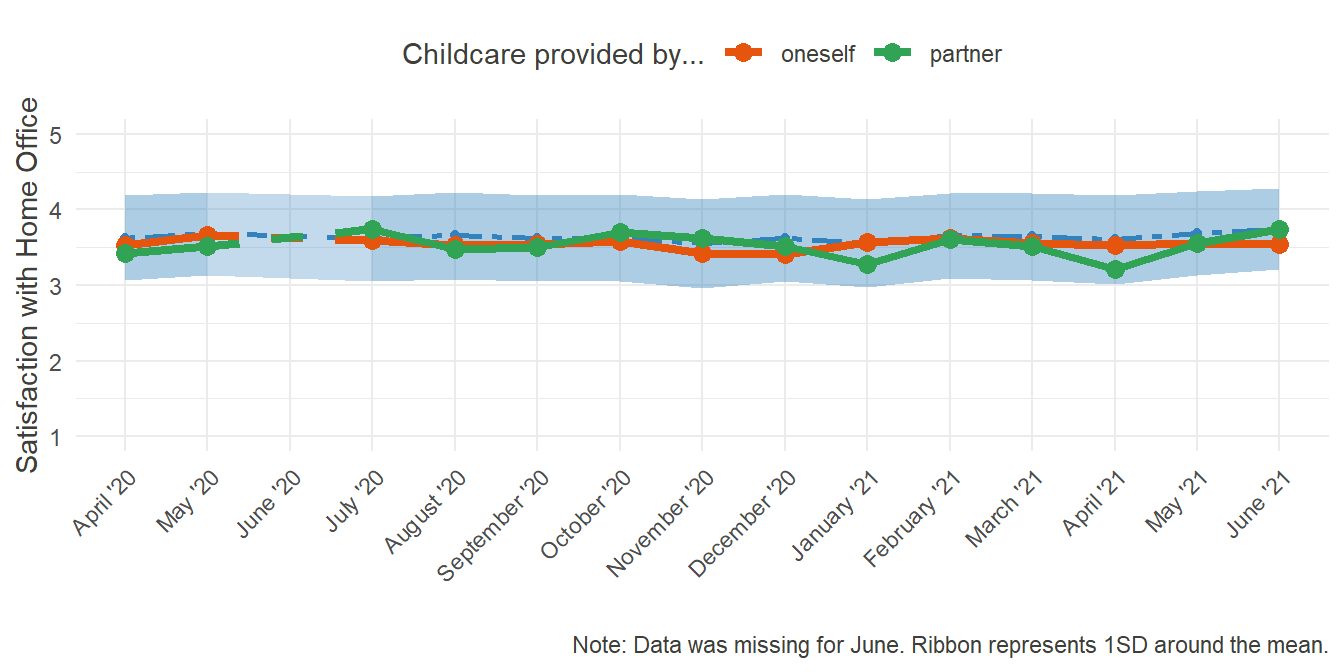
Surprisingly, whether or not one had to care for their children at home had seemingly no effect on the overall satisfaction with Home Office. At least, there is no indication for a main effect. Further down the way, a more complex investigation into corollaries and moderators might, however, uncover clearer effects.
6.3 Efficacy
Plot
# Using the reshape function for long format now
HO_Sat_Eff = reshape(
HO_Sat[,!(names(HO_Sat) %in% c("T4_HO3","T6_HO3", grep( "_covid11",names(HO_Sat), value = T)))],
# Excluding the not needed variables from the dataframe, namely the childcare variables and the equipment variables for T4 and T6
varying = list(grep( "_HO31", names(HO_Sat), value = T), grep("_HO32", names(HO_Sat), value = T)),
# Telling reshape, which variables should be compiled into one, here they are HO31 (Satisfaction) and HO32 (Efficacy) respectively
v.names = c("Sat", "Eff"),
# How should the newly created variables be called?
direction = "long",
# Reshape into which direction?
timevar = "month",
# How should the variable indicating the timepoint be called?
idvar = "ID"
# What's the Variable identifying unique observations?
)
## test reshape
# These tables can be uncommented and executed, to be sure that the reshaping was successfull. If it was, every one should return only TRUEs
# table(HO_Sat$T3_HO31 == HO_Sat_Eff[HO_Sat_Eff$month==1, "Sat"])
# table(HO_Sat$T4_HO31 == HO_Sat_Eff[HO_Sat_Eff$month==2, "Sat"])
# table(HO_Sat$T6_HO31 == HO_Sat_Eff[HO_Sat_Eff$month==3, "Sat"])
# table(HO_Sat$T7_HO31 == HO_Sat_Eff[HO_Sat_Eff$month==4, "Sat"])
# table(HO_Sat$T8_HO31 == HO_Sat_Eff[HO_Sat_Eff$month==5, "Sat"])
# table(HO_Sat$T9_HO31 == HO_Sat_Eff[HO_Sat_Eff$month==6, "Sat"])
# table(HO_Sat$T10_HO31 == HO_Sat_Eff[HO_Sat_Eff$month==7, "Sat"])
# table(HO_Sat$T11_HO31 == HO_Sat_Eff[HO_Sat_Eff$month==8, "Sat"])
#
# table(HO_Sat$T3_HO32 == HO_Sat_Eff[HO_Sat_Eff$month==1, "Eff"])
# table(HO_Sat$T4_HO32 == HO_Sat_Eff[HO_Sat_Eff$month==2, "Eff"])
# table(HO_Sat$T6_HO32 == HO_Sat_Eff[HO_Sat_Eff$month==3, "Eff"])
# table(HO_Sat$T7_HO32 == HO_Sat_Eff[HO_Sat_Eff$month==4, "Eff"])
# table(HO_Sat$T8_HO32 == HO_Sat_Eff[HO_Sat_Eff$month==5, "Eff"])
# table(HO_Sat$T9_HO32 == HO_Sat_Eff[HO_Sat_Eff$month==6, "Eff"])
# table(HO_Sat$T10_HO32 == HO_Sat_Eff[HO_Sat_Eff$month==7, "Eff"])
# table(HO_Sat$T11_HO32 == HO_Sat_Eff[HO_Sat_Eff$month==8, "Eff"])
HO_Sat_Eff$month = factor(HO_Sat_Eff$month,
labels = months_miss)
HO_Sat_Eff = HO_Sat_Eff[HO_Sat_Eff$Sat > 0 & HO_Sat_Eff$Eff >0,]
# Removing all the missing Values of satisfaction and efficay
r_Sat_Eff = round(cor(HO_Sat_Eff$Sat,HO_Sat_Eff$Eff, use = "complete.obs"), digits = 2)
HO_Sat_Eff_plot = ggplot(HO_Sat_Eff, aes(x=Eff,y= Sat)) +
geom_smooth(method = lm, size = 0.5) +
theme_minimal()+
coord_cartesian(xlim = c(1,5), ylim = c(1,5))+
scale_fill_brewer(palette = "Blues")+
labs(x="Efficacy in Home Office",y = "Satisfaction with Home Office", caption = paste0("Mean correlation over all months was .", 100*r_Sat_Eff), title = "Relationship between efficacy in and satisfaction with Home Office", subtitle = "Over all months")+
font_colour
HO_Sat_Eff_plot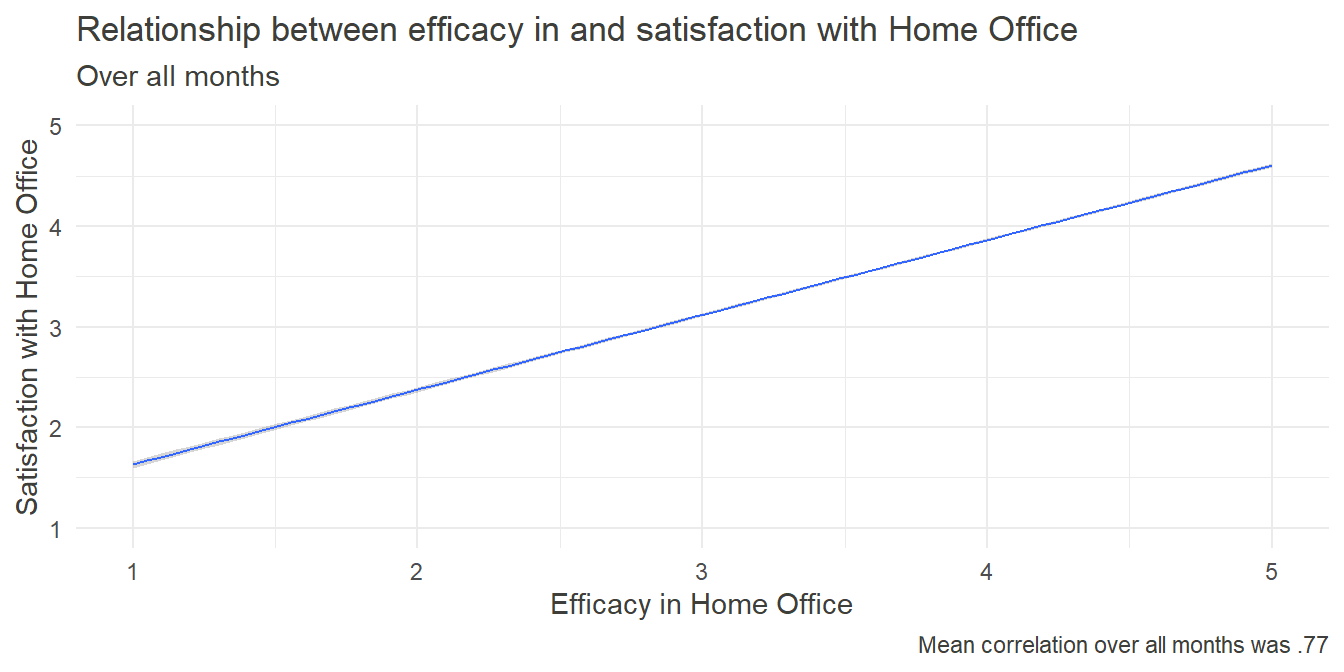
Additional Information
In general, people tend to crave a feeling of self-efficacy - that they can accomplish goals by putting in their own effort. Whether at work, while exercising one’s hobbies or in social relationships, self-efficacy - and a lack thereof - plays an integral role in forming one’s self-image and influences well-being. Therefore, we can assume, that the feeling of self-efficacy also took part in the rating of satisfaction with Home Office. The following graph shows the relationship between these two constructs over all measurement points. Upon first inspection it became obvious, that the coefficients did not vary significantly between the months.
To measure self-efficacy, we asked our participants to rate the following statement:
“I am certain that I can successfully fulfill my tasks in the Home Office.”
## For details on the code for the plots, please change to the "Plots"-Tab and unfold the code there. ##
HO_Sat_Eff_plot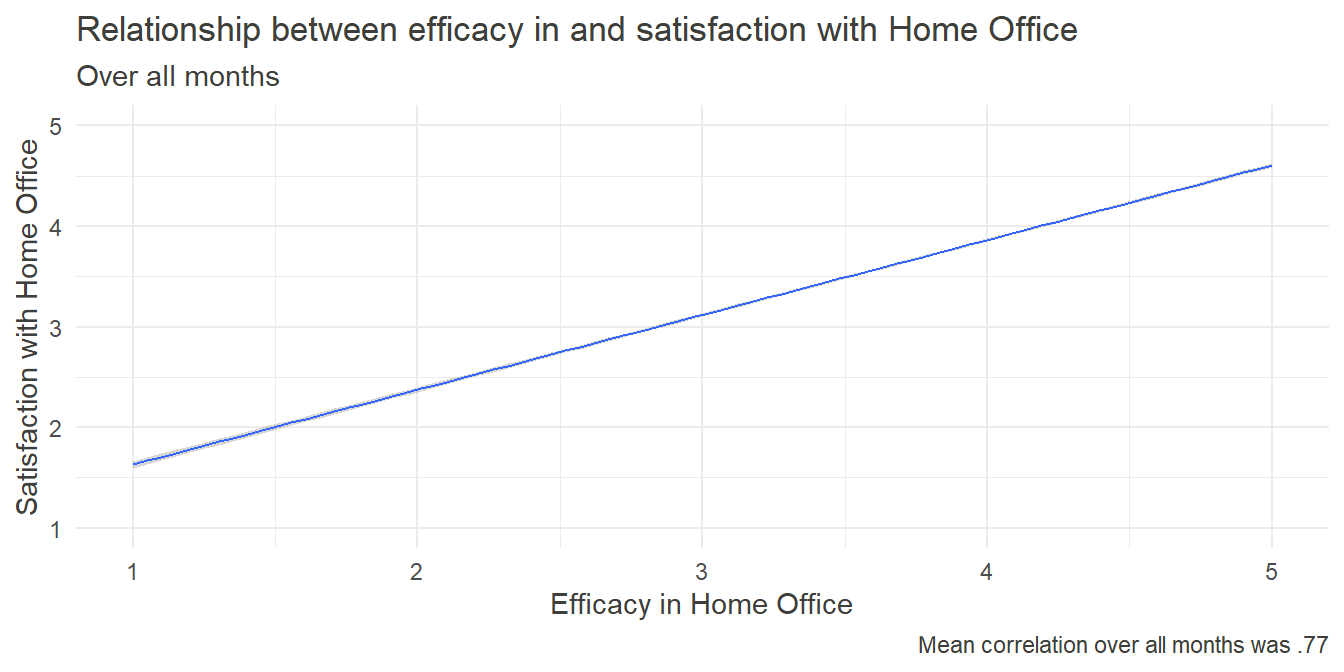
As predicted, there was a very strong relationship between satisfaction and efficacy, further emphasizing the importance of the latter. Nevertheless, this was just a quick and cursory analysis which doesn’t allow causal inference yet. A cross-lagged study predicting satisfaction in point T through efficacy at point T-1 and vice versa could give further insight into the underlying mechanisms.
6.4 Sufficient Equipment
Plot
HO_Sat_Eff$Equip_T3 = factor(HO_Sat_Eff$T3_HO3, levels = 0:2, labels = c("Missing","Insufficient", "Sufficient"))
# creating a new factor
HO_Sat_Equip=
dplyr::filter(HO_Sat_Eff,month == "April '20",Equip_T3 != "Missing" ) %>%
# Filtering the dataframe to only use the rows, where month == "April" and information about the Equipment is not "Missing"
dplyr::group_by(Equip_T3) %>%
# Grouping this filtered dataframe by the levels of Equip_T3, being Sufficient and Insufficient
dplyr::summarise(Sat_mean = mean(Sat),Sat_sd= sd(Sat))
# Applying multiple functions to the filtered and grouped dataset, namely mean to create Sat_Mean and sd to create Sat_sd
#insufficient, sufficient
HO_Equip = plyr::count(HO_Sat_Eff[HO_Sat_Eff$month == "April '20",], vars = "Equip_T3")[2:3,2]
# Counting, how many people indicated sufficient and insufficient equipment
r_Sat_Equip = round(
cor(
filter(HO_Sat_Eff,month == "April '20",Equip_T3 != "Missing" )$Sat,
filter(HO_Sat_Eff,month == "April '20",Equip_T3 != "Missing" )$T3_HO3),
digits = 2)*100
# Correlating satisfaction and equipment for the subtitle below
HO_Sat_Equip_plot = ggplot(HO_Sat_Equip, aes(y= Sat_mean, x = Equip_T3, fill =Equip_T3))+
geom_bar(stat = "identity")+
geom_errorbar(aes(ymin = Sat_mean - Sat_sd , ymax = Sat_mean + Sat_sd), width = 0.2)+
theme_minimal()+
theme(legend.position="none", panel.grid.major.x = element_blank())+
#panel.grid.major.x = element_blank() removes vertical lines from the plot
coord_cartesian(ylim = c(1,5))+
scale_fill_manual(values = c("#6baed6", "#08519c"))+
labs(x="Availability of technical equipment\n at home",
y = "Satisfaction with Home Office",
caption = paste0("Point-biserial correlation was .", r_Sat_Equip,". Errorbars\n represent one SD above and below the mean."),
title = "Relationship between \nequipment for and satisfaction \nwith Home Office",
subtitle = "In April")+
font_colour
HO_Sat_Equip_plot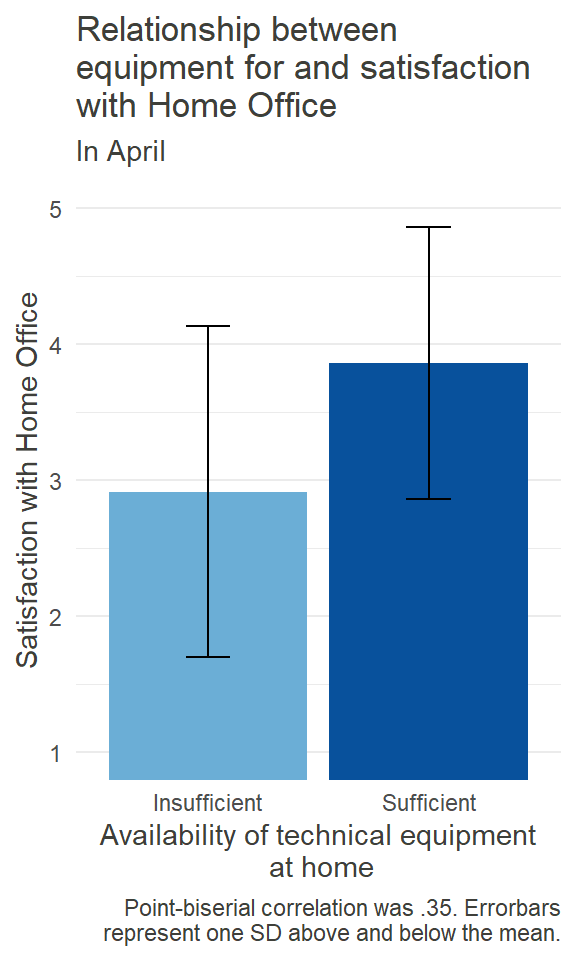
Additional Information
HO_Sat_Equip_plot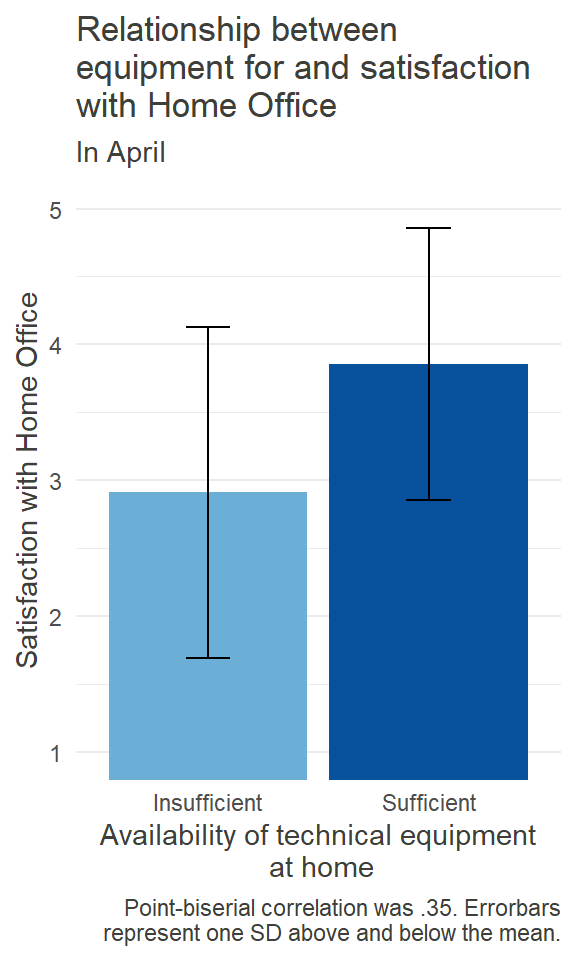
Similar to the workspace itself, having the right equipment for working at home can be important for the satisfaction experienced. What kind of equipment is needed can vary from job to job. For some, a simple laptop and a steady internet-connection could be enough (although granted, not always available), while others might need strong hardware, specific software, or special devices. So we just asked our participants in general whether or not they had sufficient technical equipment at home, as to not assume what that should include. The barplot on the left shows the results for April.
In general, 460 out of 595 (= 77.31%) participants indicated in April to have sufficient equipment when working from home. So, while most people seemed to have the right equipment at home, for the rest the insufficiency was associated with lower satisfaction. Again, statistical significance and causal analysis pending.
7 Summary and Conclusion
As stated above, the COVID-19 Crisis brought emphasis on the topic of Home Office among other things. Coerced by the circumstances, many people started working from home. Where there were hindrances before, new possibilities arose. And while both the prevalence and permission of Home Office slowly decrease, for some the boundaries were broken for good.
Questions arose beyond possibility and prevalence: How do people feel, when they work from home? How should the work be designed to yield best outcomes? In our short portrayal we could give first answers to these questions. In general, there is above average satisfaction with working in the Home Office. This seems to hold true regardless of childcare but is potentially influenced by the perception of self-efficacy and the presence of sufficient technical equipment. The feeling of professional isolation is relatively low, albeit a differentiation between those who work entirely from home is needed. When someone is in Home Office, having a designated spot to work from seems to be present for most, yet not given for everybody.
We hope, that we were able to give some insights into the topic of Home Office based on our sample and to inspire future rigorous research. We believe, that with digitalization progressing relentlessly, we as researchers and practitioners of work and organizational psychology need to be ready to give well-funded advice on how to create the best circumstances for Home Office possible.
References
#rm(list=ls())Copyright © 2020 Universität Leipzig. All rights reserved.
For correspondence regarding this page, please refer to Richard Janzen